
تفاوت کم برازش و بیش برازش در یادگیری ماشین
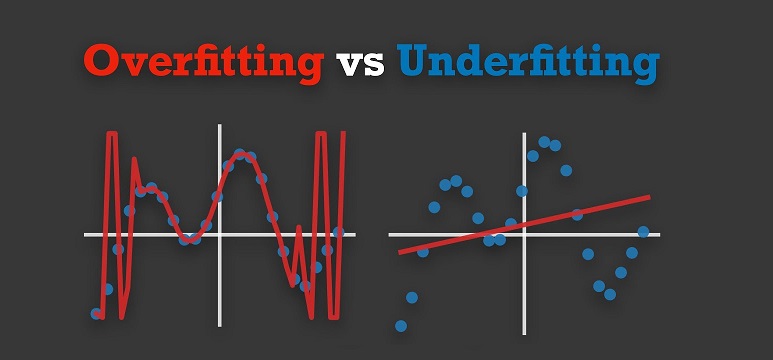

در دنیای یادگیری ماشین (Machine Learning)، یکی از چالشهای اصلی، دستیابی به مدلی است که نه تنها روی دادههای آموزشی خوب عمل کند، بلکه بتواند روی دادههای جدید و نادیده نیز پیشبینیهای دقیقی انجام دهد. دو مفهوم کلیدی که اغلب باعث شکست مدلها میشوند، کم برازش (Underfitting) و بیش برازش (Overfitting) هستند. در این مقاله، به بررسی تفاوت این دو مفهوم میپردازیم و سپس ویژگیهای یک آموزش صحیح الگوریتمهای یادگیری ماشین را توصیف میکنیم. این مفاهیم برای هر کسی که در حوزه هوش مصنوعی و دادهکاوی فعالیت میکند، ضروری هستند.
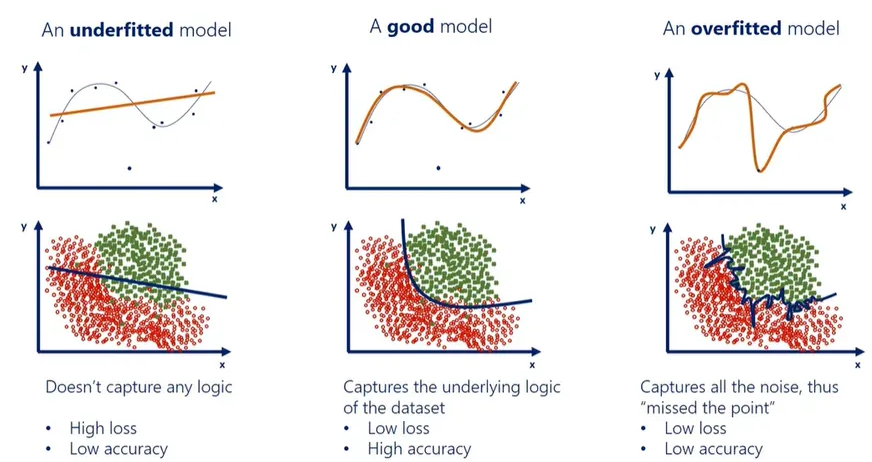
کم برازش (Underfitting) چیست؟
کم برازش زمانی رخ میدهد که مدل یادگیری ماشین بیش از حد ساده است و نمیتواند الگوهای موجود در دادههای آموزشی را به درستی تشخیص دهد. در نتیجه، مدل نه تنها روی دادههای آموزشی عملکرد ضعیفی دارد، بلکه روی دادههای تست یا واقعی نیز ناکارآمد است. این وضعیت مانند این است که سعی کنید یک منحنی پیچیده را با یک خط راست توصیف کنید – نتیجه، تقریب بسیار ضعیفی خواهد بود.
علل کم برازش:
- مدل بیش از حد ساده: مثلا استفاده از الگوریتمهایی مانند رگرسیون خطی برای دادههای غیرخطی.
- دادههای ناکافی یا نویزی: اگر دادهها کم باشند یا کیفیت پایینی داشته باشند، مدل نمیتواند الگوی داده ها را یاد بگیرد.
- پارامترهای ناکافی: مانند تعداد لایههای کم در شبکههای عصبی یا درجه پایین در مدلهای چندجمله ای.
مثال:
فرض کنید میخواهید قیمت خانهها را بر اساس متراژ پیشبینی کنید، اما دادهها نشاندهنده روابط پیچیدهتری (مانند مکان و امکانات) هستند. اگر از یک مدل خطی ساده استفاده کنید، مدل نمیتواند این پیچیدگیها را آموزش ببیند و خطای پیش بینی بالایی خواهد داشت.
بیش برازش (Overfitting) چیست؟
در مقابل، بیش برازش زمانی اتفاق میافتد که مدل بیش از حد پیچیده است و نه تنها الگوهای واقعی را یاد میگیرد، بلکه نویزها و جزئیات تصادفی دادههای آموزشی را نیز به عنوان الگو در نظر میگیرد. نتیجه این است که مدل روی دادههای آموزشی عملکرد عالی دارد، اما روی دادههای جدید شکست میخورد. این وضعیت مانند حفظ کردن تمام جزئیات یک کتاب بدون درک محتوای آن است – مدل “حفظ” میکند، اما “درک” نمیکند.
علل بیش برازش:
- مدل بیش از حد پیچیده: مانند درخت تصمیمگیری عمیق یا شبکه عصبی با لایههای زیاد بدون مرتب سازی ویژگی.
- دادههای آموزشی کم: وقتی دادهها محدود باشند، مدل به جای الگوهای کلی، به جزئیات خاص میپردازد.
- عدم استفاده از تکنیکهای منظمسازی: مانند عدم اعمال Dropout یا L2 Regularization.
مثال:
در همان مثال پیشبینی قیمت خانه، اگر مدلی بسازید که هر نقطه داده را دقیقاً فیت کند (مانند یکچند جمله ای درجه بالا)، مدل روی دادههای آموزشی عملکرد عالی دارد، اما برای خانههای جدید، پیشبینیهای اشتباهی میدهد زیرا نویزها را الگو فرض کرده است.
تفاوتهای کلیدی بین کم برازش و بیش برازش
برای درک بهتر، جدول زیر تفاوتهای اصلی این دو مفهوم را نشان میدهد:
| ویژگی | کم برازش (Underfitting) | بیش برازش (Overfitting) |
|---|---|---|
| عملکرد روی دادههای آموزشی | ضعیف (خطای بالا) | عالی (خطای پایین) |
| عملکرد روی دادههای تست | ضعیف (خطای بالا) | ضعیف (خطای بالا) |
| پیچیدگی مدل | کم (ساده) | زیاد (پیچیده) |
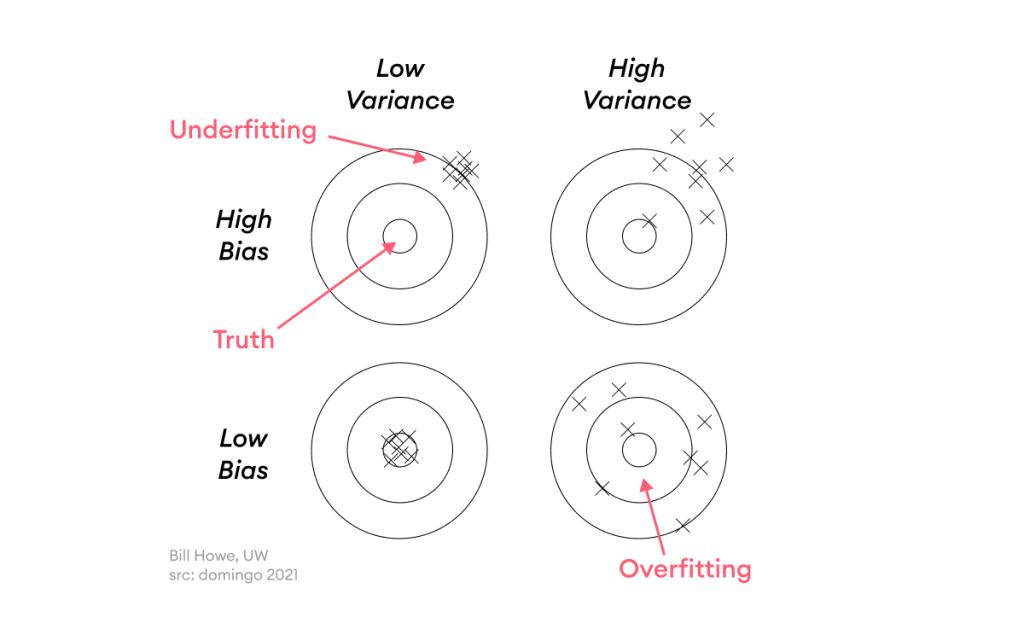
| Bias vs. Variance | Bias بالا (مدل ساده، الگوها را از دست میدهد) | Variance بالا (مدل به نویز حساس است) |
| راهحل اصلی | افزایش پیچیدگی مدل یا دادههای بیشتر | منظمسازی، کاهش پیچیدگی یا دادههای بیشتر |
کم برازش نشاندهنده “یادگیری کم” است، در حالی که بیش برازش “یادیگیری زیاد” روی دادههای خاص را نشان میدهد. مفهوم Bias-Variance Tradeoff یک مفهوم کلیدی است: Bias خطای ناشی از سادهسازی بیش از حد است، و Variance خطای ناشی از حساسیت به نویز. هدف در یادگیری ماشین، تعادل بین این دو است.
ویژگیهای یک آموزش صحیح الگوریتمهای یادگیری ماشین
برای جلوگیری از کم برازش و بیش برازش، آموزش صحیح باید بر پایه تعادل و ارزیابی مداوم باشد. یک مدل خوب، Generalization خوبی دارد، یعنی روی دادههای نادیده عملکرد مناسبی نشان میدهد. در ادامه، ویژگیهای کلیدی یک آموزش صحیح را بررسی میکنیم:
1. تقسیم دادهها به مجموعههای آموزشی، اعتبارسنجی و تست:
- حداقل 70% برای آموزش، 15% برای اعتبارسنجی (Validation) و 15% برای تست.
- اعتبارسنجی برای تنظیم hyperparameterها و جلوگیری از بیش برازش استفاده میشود.
2. استفاده از تکنیکهای منظمسازی (Regularization):
- L1/L2 Regularization: جریمه کردن وزنهای بزرگ برای جلوگیری از پیچیدگی زیاد.
- Dropout: در شبکههای عصبی، خاموش کردن تصادفی نورونها برای جلوگیری از وابستگی بیش از حد.
3. اعتبار سنجی متقابل (Cross-Validation):
- روشی مانند K-Fold برای ارزیابی مدل روی بخشهای مختلف دادهها، که کمک میکند تا ازبیش برازش جلوگیری شود.
4. توقف زودهنگام آموزش (Early Stopping):
- توقف آموزش وقتی خطای اعتبارسنجی شروع به افزایش کند، حتی اگر خطای آموزشی کاهش یابد.
5. افزایش دادهها (Data Augmentation):
- تولید دادههای جدید از دادههای موجود (مانند چرخاندن تصاویر) برای بهبود generalization.
6. انتخاب مدل مناسب:
- شروع با مدلهای ساده و افزایش پیچیدگی بر اساس نیاز. نظارت بر منحنیهای یادگیری (Learning Curves) برای تشخیص مشکلات.
7. ارزیابی با متریکهای مناسب:
- استفاده از Accuracy, Precision, Recall و F1-Score بسته به مسئله. نظارت بر تفاوت خطای آموزشی و تست.
8.تکنیکهای یادگیری ترکیبی (Ensemble Learning):
- این روشها با ترکیب چندین مدل پایه (مانند درختهای تصمیمگیری) عملکرد کلی را بهبود میبخشن و ریسک بیش برازش رو کاهش میدن. مثالها:
- Bagging (مانند Random Forest): چندین مدل روی زیرمجموعههای تصادفی دادهها آموزش داده میشن و نتایج میانگینگیری میشن تا واریانس کاهش پیدا کنه.
- Boosting (مانند XGBoost یا AdaBoost): مدلها به ترتیب ساخته میشن و هر مدل بعدی روی اشتباهات قبلی تمرکز میکنه تا بایاس و واریانس تعدیل بشه.
- Stacking: ترکیب مدلهای مختلف (مانند SVM و Neural Network) با یک مدل نهایی برای پیشبینی.
- این تکنیکها به ویژه وقتی دادهها پیچیده یا نویزی هستن، generalization رو افزایش میدن و از کم برازش جلوگیری میکنن.
با رعایت این ویژگیها، مدل شما نه تنها دقیق خواهد بود، بلکه قابل اعتماد و قابل تعمیم به دنیای واقعی.
نتیجهگیری
کم برازش و بیش برازش دو دشمن اصلی در یادگیری ماشین هستند که میتوانند تلاشهای شما را در افزایش دقت مدل، هدر دهند. با درک تفاوت آنها و اعمال تکنیکهای آموزش صحیح، میتوانید مدلهایی بسازید که واقعاً مفید باشند. اگر در حال توسعه الگوریتمهای ML هستید، همیشه generalization را اولویت دهید. برای اطلاعات بیشتر، میتوانید به منابع مانند کتاب “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” مراجعه کنید.











