
یادگیری ترکیبی Bagging


یادگیری ترکیبی Bagging
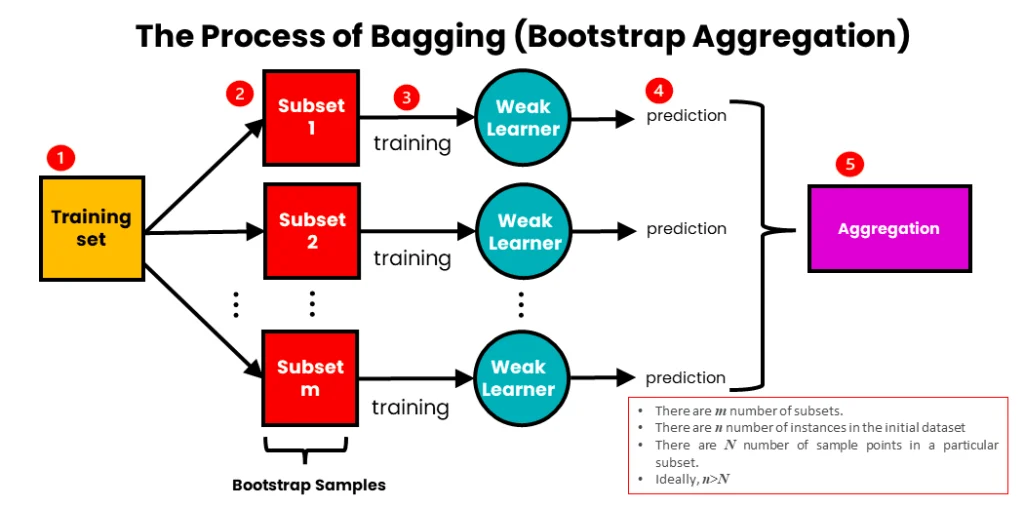
Bagging یا Bootstrap Aggregation یکی از روشهای یادگیری ترکیبی است که با هدف کاهش واریانس و جلوگیری از overfitting عمل میکند. این روش توسط لئو بریمن (Leo Breiman) در سال ۱۹۹۶ معرفی شد. ایده اصلی بگینگ این است که چندین مدل پایه (معمولاً مدلهای ضعیف مانند درخت تصمیم) را روی زیرمجموعههای مختلف از دادههای آموزشی آموزش دهیم و سپس پیشبینیهای آنها را ترکیب کنیم تا مدل نهایی قویتر و پایدارتری به دست آید.
Random Forest (جنگل تصادفی) از ترکیب صدها درخت تصمیم ساخته شده که با روش bagging آموزش داده می شود. این روش برای مدلهای ناپایدار و ساده ای مانند درخت تصمیم بسیار مؤثر است مزیت اصلی آن پایداری بیشتر و عملکرد بهتر نسبت به یک مدل منفرد درخت تصمیم است.
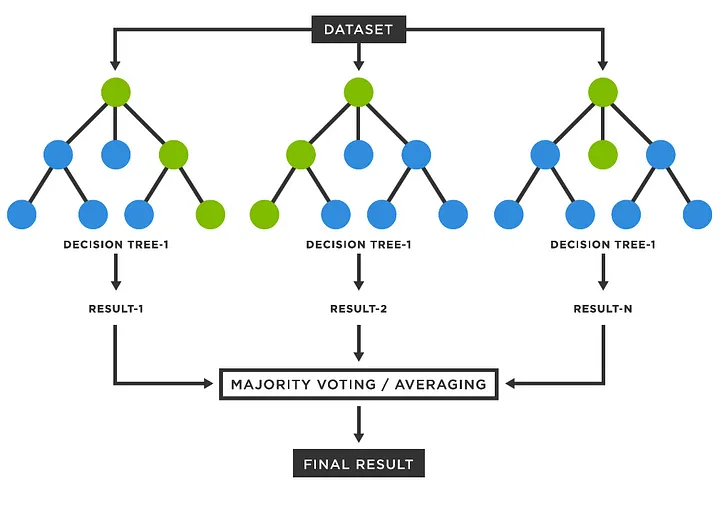
نحوه آموزش و تست دادهها
- آموزش (Training):
۱. از دادههای آموزشی اصلی، چندین زیرمجموعه (bootstrap samples) بهصورت تصادفی و با جایگزینی از مجموعه داده اصلی، ایجاد میکنیم. در نتیجه در هر زیر مجموعه داده برخی نمونهها ممکن است تکراری باشند و برخی حذف شوند. معمولاً حدود ۶۳% از دادههای اصلی در هر زیرمجموعه ظاهر میشوند.
۲. برای هر زیرمجموعه، یک مدل پایه مشابه (مثل درخت تصمیم) را به طور مستقل آموزش میدهیم. این کار برای تعداد مشخصی مدل (مثلاً ۱۰۰ یا بیشتر) تکرار میشود.
۳. هیچ تعاملی بین مدلها وجود ندارد؛ هر کدام روی زیرمجموعه خود آموزش میبیند.
4. در نهایت نتایج مدل ها با رای اکثریت (در طبقهبندی) یا میانگینگیری (در رگرسیون) ترکیب(Aggregation) میشود. - تست (Testing) یا پیشبینی:
۱. برای یک داده جدید (از مجموعه تست یا دادههای واقعی)، پیشبینی هر مدل پایه را محاسبه میکنیم.
۲. ترکیب پیشبینیها:
در مسائل طبقهبندی (Classification): از رأیگیری اکثریت (Majority Voting) استفاده میشود. مثلاً اگر ۶۰% مدلها کلاس A را پیشبینی کنند، نتیجه نهایی A است.
در مسائل رگرسیون (Regression): میانگین امتیاز پیشبینیها (scores) گرفته میشود.
این فرآیند باعث میشود مدل نهایی کمتر تحت تأثیر نویز یا دادههای خاص قرار گیرد.
مزایا
- کاهش واریانس: با ترکیب چندین مدل، نوسانات پیشبینی کاهش مییابد و مدل پایدارتر میشود.
- بهبود دقت: اغلب دقت بالاتری نسبت به یک مدل پایه دارد، به ویژه در دادههای نویزی.
- مقاوم در برابر اورفیتینگ: چون مدلها روی زیرمجموعههای متفاوت آموزش میبینند، احتمال بیشبرازش کم میشود.
- سادگی پیادهسازی: نیازی به تنظیم پارامترهای پیچیده ندارد و میتواند با مدلهای پایه ساده کار کند.
- موازیسازی آسان: آموزش مدلها میتواند به صورت موازی انجام شود، که سرعت را افزایش میدهد.
معایب
- افزایش هزینه محاسباتی: نیاز به آموزش چندین مدل، که زمان و منابع بیشتری میطلبد (هرچند با سختافزار مدرن قابل مدیریت است).
- عدم کاهش بایاس: اگر مدل پایه بایاس بالایی داشته باشد (مثل درختهای تصمیم کوتاه)، بگینگ نمیتواند آن را کاهش دهد. برای این کار، تکنیکهایی مانند بوستینگ بهتر هستند.
- کمتر مؤثر در دادههای کوچک: در مجموعههای داده کوچک، زیرمجموعهها ممکن است خیلی شبیه به هم باشند و فایده کمتری داشته باشد.
- عدم تفسیرپذیری: مدل نهایی پیچیدهتر است و درک تصمیمگیری آن سختتر از یک مدل پایه ساده.
- مصرف حافظه: ذخیره چندین مدل نیاز به فضای بیشتری دارد.
دادههای مناسب برای روش bagging
روش بگینگ بهطور کلی در یادگیری گروهی برای مجموعه دادههایی که ویژگیهای خاصی دارند، بسیار مؤثر است. نوع دادههایی که برای این روش مناسب هستند عبارتاند از:
- دادههای نویزی: بگینگ برای دادههای نویزی (مثل حسگرها، دادههای مالی یا زیستی) مناسب است، زیرا ترکیب مدلها اثر نویز را کاهش میدهد.
- دادههای با واریانس بالا: برای مدلهای حساس به تغییرات (مثل درختهای تصمیم) و دادههای پیچیده (مثل تصویر یا صوت) مؤثر است.
- دادههای چندبعدی: در دادههای با ویژگیهای زیاد (مثل دادههای ژنومی یا متنی) بهخوبی عمل میکند (مثل Random Forest).
- دادههای دستهای و پیوسته: با هر دو نوع داده کار میکند و نیاز به پیشپردازش خاصی ندارد.
- دادههای نامتوازن: با نمونهبرداری تصادفی به تعادل کمک میکند، ولی ممکن است نیاز به تکنیکهای تکمیلی (مثل SMOTE) باشد.
- دادههای بزرگ: در مجموعههای بزرگ که امکان نمونهبرداری متنوع را فراهم میکنند، عملکرد بهتری دارد.
داده های نامناسب در روش bagging
- دادههای خیلی کوچک: اگر مجموعه داده خیلی کوچک باشد (مثلاً کمتر از چند صد نمونه)، زیرمجموعههای bootstrap تفاوت زیادی با هم نخواهند داشت و بگینگ ممکن است تأثیر کمی داشته باشد.
- دادههایی با بایاس بالا: اگر دادهها به گونهای باشند که مدل پایه (مثل درختهای تصمیم کوتاه) به طور مداوم عملکرد ضعیفی داشته باشد، بگینگ نمیتواند بایاس را کاهش دهد.
- دادههای خیلی ساده: اگر روابط در دادهها خطی یا ساده باشند (مثل دادههایی که با رگرسیون خطی به خوبی مدل میشوند)، بگینگ ممکن است پیچیدگی غیرضروری ایجاد کند.
یک مثال MATLAB, Python
از مجموعه داده های دسته بندی iris کد کلاس بندی با استفاده از روش bagging نشان می دهد. درکد متلب داده های گل زنبق بارگذاری شده است. تنها دو ویژگی اول (طول و عرض کاسبرگ) برای سادهسازی تحلیل انتخاب میگردد وخروجی سه کلاس گل می باشد. سپس با مدل پایه10 درخت تصمیم با روش Bagging ؛ هر درخت بر روی نمونههای تصادفی از دادهها آموزش میبیند. در پایان، نواحی تصمیمگیری مدل بر اساس خروجی آن رسم شده و عملکرد طبقهبندی بهصورت بصری نمایش داده میشود.
%MATLAB CODE
% Load Iris dataset
load fisheriris
X = meas(:, 1:2); % Use first two features: sepal length & sepal width
Y = species;
% Convert species to numeric labels
Y_numeric = grp2idx(Y);
% Train Bagging ensemble
bagModel = fitcensemble(X, Y_numeric, 'Method', 'Bag', ...
'Learners', templateTree(), 'NumLearningCycles', 10);
% Create grid for decision boundary
[x1Grid, x2Grid] = meshgrid(linspace(min(X(:,1))-1, max(X(:,1))+1, 100), ...
linspace(min(X(:,2))-1, max(X(:,2))+1, 100));
XGrid = [x1Grid(:), x2Grid(:)];
predictedLabels = predict(bagModel, XGrid);
% Plot
figure;
gscatter(X(:,1), X(:,2), Y_numeric, 'rgb', 'o', 8);
hold on;
contourf(x1Grid, x2Grid, reshape(predictedLabels, size(x1Grid)), ...
'LineColor', 'none', 'FaceAlpha', 0.3);
title('Bagging Decision Trees on Iris Dataset');
xlabel('Sepal length');
ylabel('Sepal width');
legend('Setosa','Versicolor','Virginica');
hold off;
در کد پایتون، پس از وارد کردن کتابخانه های مورد نیاز، داده های گل زنبق بارگذاری شده است. تنها دو ویژگی اول (طول و عرض کاسبرگ) برای سادهسازی تحلیل انتخاب میگردد. سپس یک مدل یادگیری ensemble با روش Bagging ساخته میشود که شامل 10 درخت تصمیم است؛ هر درخت بر روی نمونههای تصادفی از دادهها آموزش میبیند. در پایان، نواحی تصمیمگیری مدل بر اساس خروجی آن رسم شده و عملکرد طبقهبندی بهصورت بصری نمایش داده میشود.
# PTHON CODE
from sklearn.datasets import load_iris
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import numpy as np
# Load Iris dataset
iris = load_iris()
X = iris.data[:, :2] # Use first two features: sepal length & sepal width
y = iris.target
# Train Bagging classifier
model = BaggingClassifier(
base_estimator=DecisionTreeClassifier(),
n_estimators=10,
random_state=0
)
model.fit(X, y)
# Plot decision boundaries
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.4, cmap=plt.cm.coolwarm)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolor='k', cmap=plt.cm.coolwarm)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('Bagging Decision Trees on Iris Dataset')
plt.show()











