چالش (ILSVRC)


هدف از چالش (ILSVRC)
چالش ImageNet Large Scale Visual Recognition Challenge (ILSVRC) یک رقابت سالانه در حوزه بینایی رایانه بود که هدف اصلی آن ارزیابی و مقایسه الگوریتمهای تشخیص اشیاء (object detection) و طبقهبندی تصاویر (image classification) در مقیاس بزرگ بود. این چالش برای اندازهگیری پیشرفت در زمینه بینایی رایانه، شاخصگذاری تصاویر، بازیابی و حاشیهنویسی خودکار طراحی شده بود. تمرکز آن روی حل مسائل واقعی مانند شناسایی دستهبندیهای مختلف اشیاء در تصاویر روزمره بود و نقش کلیدی در نشان دادن اثربخشی شبکههای عصبی عمیق (مانند CNNها) داشت. این رقابت از سال ۲۰۱۰ شروع شد و تا ۲۰۱۷ ادامه داشت، اما پس از آن متوقف شد زیرا بنچمارک آن “حلشده” تلقی میشد و دیگر چالشبرانگیز نبود. برنامهریزی برای یک رقابت جدید با تمرکز روی تصاویر سهبعدی در سال ۲۰۱۸ وجود داشت، اما محقق نشد و رقابت اصلی دیگر برگزار نمیشود.
سالهای برگزاری
رقابت ILSVRC از سال ۲۰۱۰ تا ۲۰۱۷ به صورت سالانه برگزار شد و بیش از ۵۰ موسسه و تیم از سراسر جهان در آن شرکت کردند. در سالهای اولیه، تمرکز روی روشهای سنتی مانند SVM بود، اما از ۲۰۱۲ به بعد، شبکههای عصبی عمیق غالب شدند.
دیتاست پایه (ImageNet)
دیتاست ImageNet یک مجموعه بزرگ از تصاویر است که بیش از ۱۵ میلیون تصویر با رزولوشن بالا را شامل میشود و با بیش از ۲۲ هزار کلاس (دستهبندی) برچسبگذاری شده است. این تصاویر از وب جمعآوری شده و با کمک crowd-sourcing (مانند Amazon Mechanical Turk) برچسبگذاری شدهاند. برای چالش ILSVRC، از زیرمجموعهای به نام ImageNet-1K (یا ILSVRC2012-2017) استفاده میشد که شامل:
- حدود ۱.۲۸ میلیون تصویر آموزشی (training images)
- ۵۰ هزار تصویر اعتبارسنجی (validation images)
- ۱۰۰ هزار تصویر تست (test images)
در ۱۰۰۰ کلاس غیرهمپوشان (non-overlapping classes) بود. هر کلاس معمولاً یک دستهبندی خاص مانند نژادهای سگ یا اشیاء روزمره است. تصاویر RGB هستند و اغلب به اندازه استاندارد (مانند ۲۲۴x۲۲۴) پیشپردازش میشوند. برخی تصاویر دارای bounding box برای تشخیص اشیاء و ویژگیهایی مانند رنگ، الگو و شکل هستند. این دیتاست اکنون روی پلتفرمهایی مانند Kaggle در دسترس است.
برندگان و مدلهای شبکهای
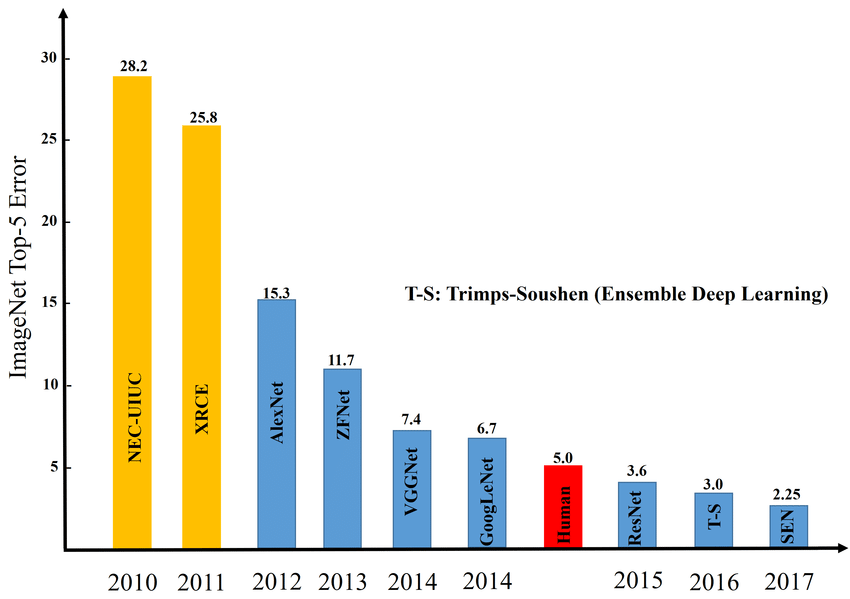
رقابت معمولاً شامل وظایف طبقهبندی (classification)، محلیسازی (localization) و تشخیص اشیاء بود، اما تمرکز اصلی روی طبقهبندی با معیار top-5 error rate (احتمال اینکه پاسخ درست در میان ۵ پیشبینی برتر نباشد) بود. در ادامه، لیست برندگان وظیفه طبقهبندی برای هر سال، همراه با نام مدل (اگر موجود)، نرخ خطا و ویژگیهای کلیدی شبکههای پیشنهادی آورده شده است. این مدلها پیشرفتهای کلیدی در یادگیری عمیق را نشان میدهند:
سال ۲۰۱۰
در سال ۲۰۱۰، تیم NEC Labs America با استفاده از روش مبتنی بر SVM برنده چالش ILSVRC شد و نرخ خطای top-5 آن حدود ۲۸% (با دقت top-5 برابر ۷۱.۸%) بود. این مدل از ویژگیهای دستی مانند Histogram of Oriented Gradients (HoG) و Local Binary Patterns (LBP) بهره میبرد و شامل کدگذاری مختصات محلی و pooling بود. آموزش روی سه ماشین ۸-هستهای در چهار روز انجام شد و تمرکز اصلی روی روشهای سنتی بدون استفاده از شبکههای عصبی عمیق بود، که نشاندهنده رویکردهای اولیه در طبقهبندی تصاویر قبل از انقلاب یادگیری عمیق است.
سال ۲۰۱۱
در سال ۲۰۱۱، تیم XRCE با رهبری Florent Perronnin و Jorge Sanchez برنده شد و نرخ خطای top-5 را به ۲۵.۸% رساند. این مدل از SVM خطی با Fisher vectors کوانتیزهشده استفاده میکرد و بهبودهایی در استخراج ویژگیها بدون نیاز به یادگیری عمیق ایجاد کرد. این رویکرد کارآمدتر از سال قبل بود و نشان داد که روشهای سنتی هنوز میتوانند پیشرفت کنند، اما مقدمهای برای ورود شبکههای عمیق در سالهای بعد شد.
سال ۲۰۱۲
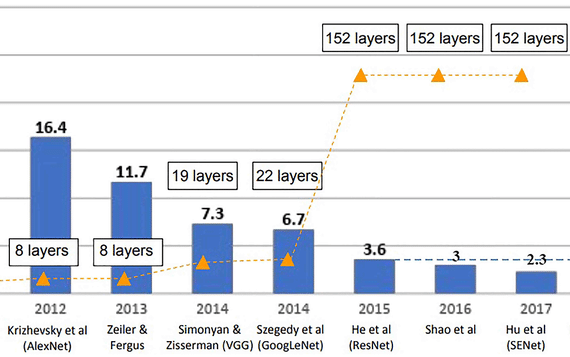
سال ۲۰۱۲ نقطه عطفی بود که تیم SuperVision با مدل AlexNet (طراحیشده توسط Alex Krizhevsky، Ilya Sutskever و Geoffrey Hinton) برنده شد و نرخ خطای top-5 را به ۱۵.۳% کاهش داد. این اولین CNN عمیق موفق با ۸ لایه (۵ لایه کانولوشنال و ۳ لایه کاملاً متصل) بود و ویژگیهایی مانند فعالسازی ReLU، dropout برای جلوگیری از overfit، data augmentation و آموزش روی GPU داشت. این مدل انقلاب در یادگیری عمیق ایجاد کرد و نشان داد که شبکههای عصبی میتوانند عملکرد بسیار بهتری نسبت به روشهای سنتی داشته باشند.
سال ۲۰۱۳
در چالش ILSVRC 2013، مدل ZFNet (این مدل اساساً یک نسخه بهبودیافته و بهینهشده از AlexNet است) توسط تیم Clarifai استفاده شد و برنده وظیفه طبقهبندی تصاویر شد، هرچند در رتبهبندی رسمی، Clarifai به عنوان برنده اعلام شد که از ensemble learning (یادگیری گروهی) از چندین CNN بزرگ، از جمله ZFNet، بهره میبرد. نرخ خطای top-5 این مدل حدود ۱۱.۷% بود.
ZFNet در برخی رتبهبندیها در جایگاه دوم در نظر گرفته میشود، اما به دلیل تأثیرش، اغلب به عنوان برنده نمادین سال ۲۰۱۳ شناخته میشود. در سالهای بعد، ایدههای ZFNet (مانند visualization) در مدلهایی مانند VGGNet و GoogLeNet تأثیرگذار بود.
سال ۲۰۱۴
سال ۲۰۱۴ شاهد برنده شدن تیم Google با مدل GoogLeNet (یا Inception v1) بود که نرخ خطای top-5 را به ۶.۶۷% کاهش داد. معماری Inception با ماژولهای چندمقیاسه برای کاهش پارامترها طراحی شده بود و ویژگیهایی مانند فیلترهای ۱x۱ برای کاهش ابعاد، pooling موازی و عمق ۲۲ لایه بدون افزایش زیاد محاسبات داشت. این مدل پایهای برای نسخههای بعدی Inception (مانند v3 و v4) شد.
VGGNet، توسعهیافته توسط تیم VGG (Visual Geometry Group) از دانشگاه آکسفورد، در چالش ILSVRC 2014 در رده دوم قرار گرفت. نرخ خطای top-5 در مدل VGGNet حدود ۷.۳% داشت، که تنها کمی بالاتر از GoogLeNet (با ۶.۶۷%) بود. VGGNet به دلیل قابلیت تعمیمپذیری و استفاده گسترده در انتقال یادگیری (transfer learning) به یکی از مدلهای پایهای در بینایی رایانه تبدیل شد.
سال ۲۰۱۵
در سال ۲۰۱۵، تیم Microsoft با مدل ResNet برنده شد و نرخ خطای top-5 را به ۳.۵۷% رساند. این مدل اتصالات باقیمانده (residual connections) را معرفی کرد تا شبکههای بسیار عمیق (۱۵۲ لایه) را آموزش دهد و ویژگیهایی مانند جلوگیری از vanishing gradient و batch normalization داشت. عملکرد آن در برخی موارد بهتر از انسان بود و این نوآوری کلیدی در حل مشکل آموزش شبکههای عمیق شد.
سال ۲۰۱۶
در سال ۲۰۱۶، تیم Trimps-Soushen با نرخ خطای top-5 حدود ۲.۹۹% (روی تست ست) برنده شد، که اولین باری بود که این نرخ زیر ۳% رفت (عملکرد انسان حدود ۵.۱% است). این نتیجه با ensemble از ۵ مدل به دست آمد و مدلهای ResNeXt (دوم) و PolyNet را پشت سر گذاشت. این مجموعه شامل ۶ شبکه مانند Inception v3/v4، Inception-ResNet v2، ResNet-200 و Wide ResNet-68/3 بود و ویژگیهایی مانند ترکیب Inception (ماژولهای کارآمد) با ResNet (شبکه باقیمانده) و عرض بیشتر در لایهها برای بهبود دقت داشت.
تیم از مدلهای pre-trained (آموزشدیده قبلی) استفاده کرد و هیچ معماری جدیدی پیشنهاد نداد، اما تمرکز روی ensemble learning و fusion (ترکیب ویژگیها) داشت. رویکرد Trimps-Soushen نشان داد که بدون نوآوری معماری، با ترکیب مدلهای موجود (مانند Inception و ResNet) و fusion هوشمند، میتوان به دقتهای انسانی یا بهتر رسید. این روش در وظایف دیگر مانند تشخیص اشیاء (object detection) در COCO 2016 نیز موفق بود.
سال ۲۰۱۷
در سال ۲۰۱۷، تیم Momenta با مدل SENet (Squeeze-and-Excitation Network) برنده شد و نرخ خطای top-5 را به ۲.۲۵۱% کاهش داد. این مدل بلوک Squeeze-and-Excitation را برای توجه به کانالها معرفی کرد و ویژگیهایی مانند بهبود مدلهای موجود مانند ResNet با وزندهی دینامیک به کانالها داشت، که بدون افزایش زیاد پیچیدگی، خطا را کاهش میداد. در این سال، ۲۹ تیم از ۳۸ تیم بالای ۹۵% دقت داشتند و نشاندهنده بلوغ فناوری بود که منجر به پایان چالش شد.