
RCNN: شبکه عصبی کانولوشنی مبتنی بر ناحیه


RCNN: شبکه عصبی کانولوشنی مبتنی بر ناحیه
در دنیای هوش مصنوعی و بینایی رایانه، تشخیص اشیاء (Object Detection) یکی از چالشهای کلیدی است. تصور کنید میخواهید در یک تصویر، موقعیت و نوع اشیاء مختلف مانند خودروها، افراد یا حیوانات را شناسایی کنید. روشهای سنتی مانند تکنیک پنجره لغزان (Sliding Window) با وجود سادگی، از نظر محاسباتی بسیار سنگین هستند.
RCNN(Region-Based Convolutional Neural Network) که توسط راس گریشیک و همکارانش در سال ۲۰۱۴ معرفی شد، انقلابی در این زمینه ایجاد کرد. این مدل با ترکیب الگوریتمهای پیشنهاد ناحیه (Region Proposal) و شبکههای عصبی کانولوشنی (CNN)، دقت و کارایی را به طور چشمگیری افزایش داد. در این مقاله، به طور گامبهگام به بررسی RCNN میپردازیم،
تکنیک پنجره لغزان در تشخیص اشیاء: مشکلی قدیمی
قبل از RCNN، روش رایج تشخیص اشیاء، استفاده از پنجرههای لغزان بود. در این روش، یک پنجره مستطیلشکل با اندازههای مختلف (برای پوشش نسبتهای ابعادی متنوع) روی تصویر حرکت میکند و هر بخش را به یک طبقهبند (Classifier) ارسال میکند. اما این رویکرد مشکلات زیادی دارد:
- هزینه محاسباتی بالا: برای یک تصویر ۵۰۰x۳۰۰ پیکسل، ممکن است هزاران پنجره (مثلاً ۲۰۰۰ پنجره برای هر مقیاس) تولید شود، که هر کدام باید از طریق CNN پردازش شوند.
- عدم انعطافپذیری: پوشش نسبتهای ابعادی مختلف (مانند اشیاء کشیده یا مربعی) نیاز به تولید پنجرههای متنوع دارد، که حجم کار را افزایش میدهد.

اندازه پنجره و اندازه گام حرکت آن (step size) از پارامترهای مهمی هستند که بر دقت و سرعت تشخیص تأثیر میگذارند. اما RCNN با حل این مشکلات، تمرکز را روی نواحی احتمالی اشیاء (Region Proposals) میگذارد تا از پردازش بیهوده جلوگیری کند.
استراتژیهای افزایش سرعت در تشخیص اشیاء
برای بهبود سرعت در تشخیص اشیاء با استفاده از شبکههای عصبی، دو رویکرد کلی وجود دارد:
- افزایش سرعت شبکههای عصبی (CNN):
این کار معمولاً با استفاده از معماریهای سبکتر (مانند MobileNet یا SqueezeNet) یا استفاده از سختافزارهای خاص (مثل GPU و TPU) انجام میشود. - کاهش تعداد تصاویر ورودی به CNN:
اینجاست که الگوریتمهای پیشنهاد ناحیه (Region Proposal) مثل Selective Search وارد عمل میشوند. بهجای اسکن کردن کل تصویر با میلیونها پنجره، Selective Search حدود ۲۰۰۰ ناحیهی معنادار را پیشنهاد میدهد که احتمال دارد در آنها شیء وجود داشته باشد.
Selective Search — پیشنهاد نواحی معنادار
Selective Search هستهی اصلی مدل RCNN است. این الگوریتم بدون نیاز به داده آموزشی (Unsupervised)، نواحی محتمل برای وجود اشیاء را پیشنهاد میدهد. بهجای استفاده از پنجرههایی با اندازه ثابت، از منطق شباهت نواحی استفاده میکند.
مراحل اصلی Selective Search:
1. تقسیمبندی تصویر به سوپرپیکسلها:
ابتدا تصویر به نواحی کوچک و همگن تقسیم میشود، مثلاً با الگوریتمهای Felzenszwalb یا SLIC. این سوپرپیکسلها بر اساس رنگ، بافت و ساختار محلی ایجاد میشوند.

2. محاسبه شباهت بین نواحی:
هر دو ناحیهی مجاور با هم مقایسه میشوند و یک وزن شباهت بر اساس معیارهای زیر دریافت میکنند:
- رنگ: در فضاهای رنگی مختلف مانند RGB یا LAB
- بافت: با استفاده از هیستوگرام LBP و فاصله Chi-Square
- اندازه: تفاوت مساحت بین دو ناحیه
- شکل: با استفاده از فاصلههای هندسی مثل Hausdorff
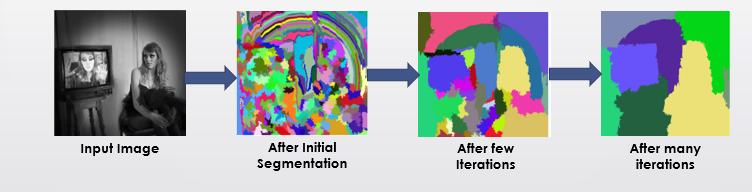
3. ادغام سلسلهمراتبی:
نواحیای که بیشترین شباهت را دارند، یکییکی با هم ادغام میشوند. این روند آنقدر تکرار میشود تا حدود ۲۰۰۰ ناحیه پیشنهادی بهدست آید. هر ناحیه با یک جعبه مرزی (Bounding Box) نمایش داده میشود.
این روش نواحی با ابعاد و نسبتهای متنوع تولید میکند و تا حدود ۵۰٪ اشیاء را با دقت بالا (IoU بیش از ۰.۷) پوشش میدهد.
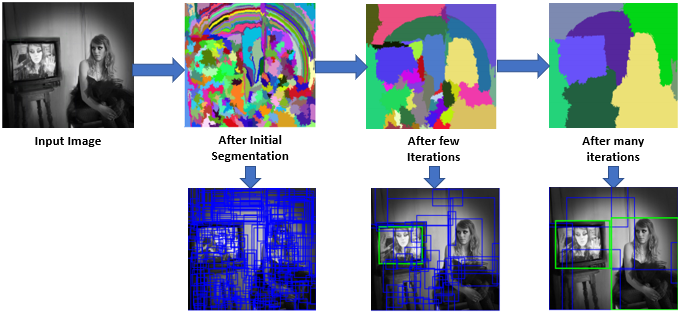
مثال بصری مراحل RCNN:
حال که با روش انتخاب نوحی معنا دار آشنا شدیم ، درک الگوریتم RCNN با یک مثال تصویری پیش می بریم.
گام ۱: دریافت تصویر ورودی
ابتدا، یک تصویر به عنوان ورودی گرفته میشود. این تصویر خام است و حاوی اشیاء احتمالی برای تشخیص است.

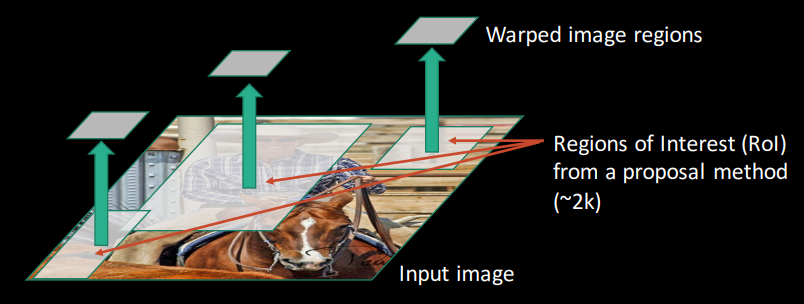
گام ۲: استخراج نواحی پیشنهادی (Regions of Interest – ROI) با استفاده از روش پیشنهادی (مانند Selective Search)
در این گام، نواحی احتمالی حاوی اشیاء با استفاده از الگوریتمی مانند Selective Search شناسایی میشوند. حدود ۲۰۰۰ ناحیه احتمالی (جعبههای مرزی) تولید میشود تا از اسکن کل تصویر جلوگیری شود.

برچسبگذاری نواحی:
هر ناحیه پیشنهادی با جعبههای واقعی (Ground Truth) مقایسه میشود. با محاسبه IOU ناحیه پیشنهادی با ناحیه شی اصلی سه برچسب برای ناحیه پیشنهادی در نظر گرفته می شود:
- مثبت (Positive): اگر IoU > ۰.۵
- منفی (Negative): اگر IoU ≤ ۰.۳
- خنثی (Neutral): بین ۰.۳ و ۰.۵ (نادیده گرفته میشود)
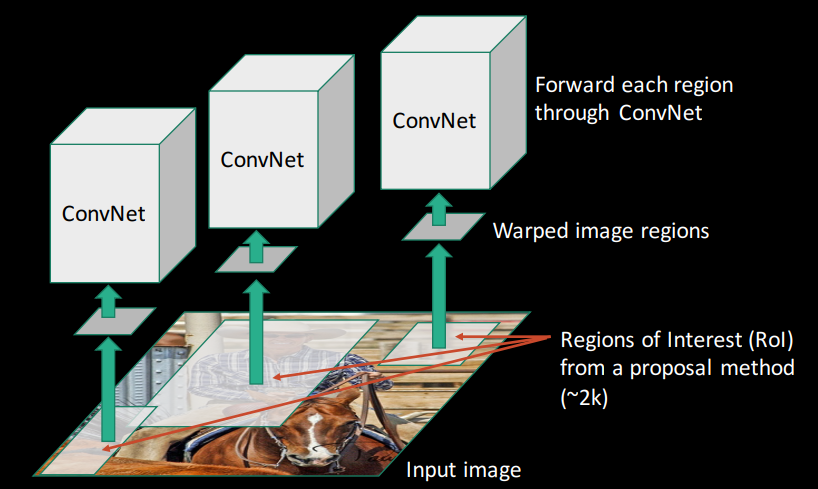
گام ۳: تغییر شکل (Reshape) نواحی و ارسال به شبکه CNN
هر ناحیه پیشنهادی به اندازه ثابت (مثلاً ۲۲۷×۲۲۷ پیکسل برای AlexNet) تغییر شکل (Warped) داده میشود.
و به شبکه عصبی کانولوشنی (CNN) از پیشآموزشدیده ارسال میگردد. لایه آخر CNN برای استخراج ویژگیهای عمومی حذف میشود.
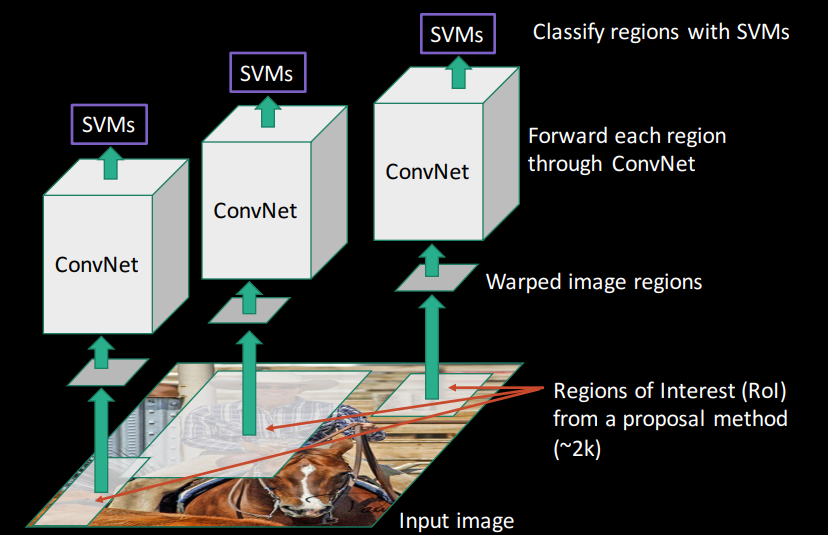
گام ۴: استخراج ویژگی با CNN و طبقهبندی با SVM
پس از استخراج ویژگی از شبکه کانولوشنی، ویژگیهای استخراجشده از هر ناحیه به یک سری SVM خطی داده میشود — یک SVM برای هر کلاس (و یکی برای پسزمینه).
- روش One-vs-All: هر SVM یاد میگیرد که بین یک کلاس خاص و باقی کلاسها (یا پسزمینه) تمایز قائل شود.
- آموزش: فقط با استفاده از نواحی مثبت و منفی (خنثیها حذف میشوند).
- پیشبینی: SVM برای هر ناحیه یک امتیاز کلاس تولید میکند. کلاسی که بالاترین امتیاز را بدهد، به عنوان پیشبینی انتخاب میشود.
گام ۵: رگرسیون جعبه مرزی (Bounding Box Regression) برای جعبههای دقیقتر
هر ناحیهای که توسط الگوریتم Selective Search پیشنهاد میشود، دارای یک جعبه مرزی مستطیلی اولیه است که بهصورت تقریبی محل حضور شیء را مشخص میکند. با این حال، این جعبهها اغلب دقت کافی ندارند و نیاز به اصلاح دارند تا با موقعیت واقعی اشیاء در تصویر هماهنگ شوند.
بنابراین .پس از طبقهبندی، یک مدل رگرسیون خطی برای مکان یابی دقیق جعبههای مرزی استفاده میشود تا موقعیت و اندازه دقیقتری برای هر شیء پیشبینی شود.
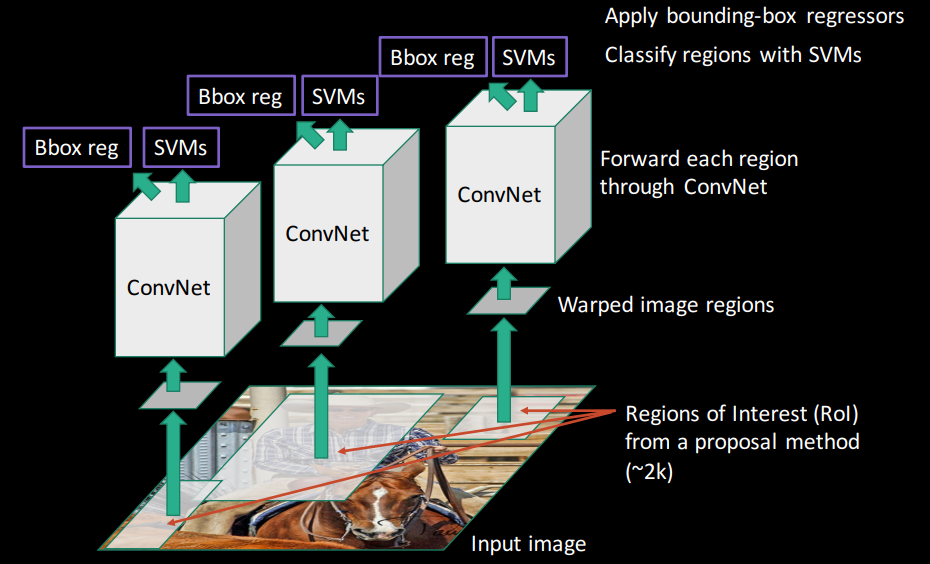
این مرحله فقط روی نواحی مثبت IoU > ۰.۵ آموزش میبیند. بهمنظور افزایش دقت در تعیین موقعیت اشیاء، از یک مدل رگرسیونی بهره گرفته میشود که بر عنوان ورودی ویژگیهای استخراجشده از شبکه عصبی کانولوشنی (CNN) و موقعیت مکانی اولیه جعبه ها می گیرد.
در نهایت به عنوان خروجی، چهار پارامتر اصلاحی شامل جابجایی در محورهای افقی و عمودی (Δx و Δy) و تغییرات در عرض و ارتفاع جعبه (Δw و Δh) را پیشبینی میکند. با اعمال این اصلاحات بر جعبههای اولیه، مختصات و ابعاد آنها به گونهای بهروز میشود که جعبه نهایی با دقت بیشتری شیء مورد نظر را دربر بگیرد.
گام 6: حذف جعبههای تکراری (Non-Maximum Suppression – NMS):
پس از اصلاح جعبهها، ممکن است چندین جعبهی بسیار مشابه و همپوشان برای یک شیء خاص تولید شده باشند. برای رفع این مشکل، از الگوریتم Non-Maximum Suppression استفاده میشود. این الگوریتم جعبههایی را که همپوشانی زیادی (IoU بالا) با یکدیگر دارند، بررسی کرده و تنها جعبهای را که بالاترین امتیاز طبقهبندی را دارد حفظ میکند. بهواسطهی این فرآیند، تنها جعبههای نهایی، دقیق و غیرتکراری باقی میمانند و بهعنوان خروجی نهایی بر روی تصویر نمایش داده میشوند.
مزایا و محدودیتهای RCNN
مزایا:
- دقت بالا:
R-CNN توانست در مقایسه با روشهای سنتی و قبل از خود، به دقت بسیار بالاتری در تشخیص اشیاء دست یابد. استفاده از شبکههای عصبی کانولوشنی (CNN) برای استخراج ویژگیها، باعث شد تا ویژگیهای پیچیدهتری از تصاویر شناسایی شود و در نتیجه دقت نهایی افزایش یابد. - قابلیت تعمیم بالا:
این مدل توانایی خوبی در یادگیری از دادههای متنوع دارد و میتواند برای تصاویر مختلف با موضوعات گوناگون آموزش داده شود. این ویژگی باعث شده که R-CNN در حوزههای کاربردی متعددی، از پزشکی گرفته تا خودروهای خودران، قابل استفاده باشد. - بستر تحقیقاتی مناسب:
R-CNN نقطه شروع موجی از تحقیقات جدید در حوزه تشخیص اشیاء مبتنی بر یادگیری عمیق بود. معماری ماژولار و قابل گسترش آن، امکان بررسی و توسعه بخشهای مختلف مانند پیشنهاد ناحیه، استخراج ویژگی یا طبقهبندی را فراهم کرد. - الهامبخش مدلهای پیشرفتهتر:
مدلهایی مانند Fast R-CNN و Faster R-CNN مستقیماً از معماری R-CNN الهام گرفتند و توانستند با حفظ دقت، سرعت و کارایی را بهطور قابل توجهی افزایش دهند. - سازگاری با تکنولوژیهای مدرن:
R-CNN با بهرهگیری از CNN و الگوریتمهای یادگیری ماشین، بهخوبی با روندهای پیشرفت تکنولوژی هماهنگ شد و بنیانگذار الگوریتمهای پیچیدهتر و سریعتر در آینده شد.
معایب:
- سرعت پایین پردازش:
بزرگترین مشکل R-CNN، کندی آن بود. برای هر تصویر، حدود ۲۰۰۰ ناحیه پیشنهادی باید بهطور جداگانه به شبکه CNN داده شوند تا ویژگیهایشان استخراج شود. این فرآیند بسیار زمانبر بود و اجرای آن در زمان حقیقی (Real-Time) را دشوار میکرد. - نیاز به قدرت محاسباتی بالا:
اجرای مدل برای هر تصویر نیازمند صدها یا هزاران بار فراخوانی CNN بود، که باعث مصرف بالای منابع سختافزاری و انرژی میشد. این موضوع استفاده از R-CNN را در دستگاههایی با منابع محدود دشوار میکرد. - عملکرد ضعیف در شناسایی اشیاء کوچک یا مشابه:
به دلیل وابستگی به نواحی پیشنهادی اولیه، R-CNN گاهی در شناسایی اشیاء کوچک یا اشیایی که ظاهری مشابه دارند، دقت کافی نداشت. - وابستگی به کیفیت تصویر:
مدل برای عملکرد مؤثر به تصاویر با وضوح و کیفیت بالا نیاز دارد. تصاویر تار، نویزی یا کمکیفیت میتوانند دقت مدل را بهطور قابل توجهی کاهش دهند. - عدم انعطافپذیری در یادگیری اشیاء جدید:
برای اضافهکردن کلاسهای جدید یا بهروزرسانی مدل، باید کل فرایند آموزش از ابتدا انجام شود که زمانبر و پرهزینه است. - مصرف بالای حافظه:
در فرایند استخراج ویژگی، مقدار زیادی داده میانی تولید میشود که باید ذخیره و مدیریت شود. این موضوع به حافظه بالایی نیاز دارد که ممکن است در برخی سیستمها در دسترس نباشد. - پیچیدگی فرایند آموزش:
آموزش مدل R-CNN شامل چندین مرحله جداگانه است: آموزش CNN برای استخراج ویژگی، آموزش SVM برای طبقهبندی، و آموزش رگرسور برای تنظیم جعبههای مرزی. این مراحل بهصورت مجزا انجام میشوند و اشتراک محاسباتی کمی دارند، که فرایند کلی را پیچیده و کند میکند.
جمعبندی
برای جمع بندی نمای کلی این الگوریتم در شکل زیر نشان داده شده است.
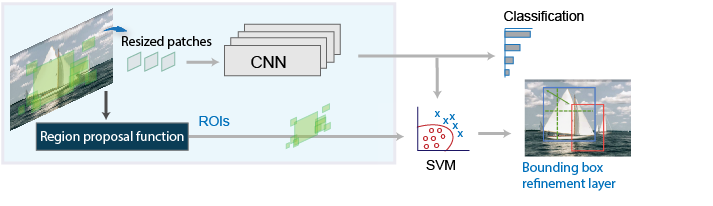
مدل RCNN تحول بزرگی در تشخیص اشیاء ایجاد کرد و پایهگذار مدلهای پیشرفتهتری مثل Fast RCNN و Faster RCNN شد. اگرچه کند است و آموزش آن زمانبر است، اما درک اصول آن برای یادگیری روشهای مدرن بسیار ارزشمند است. برای پیادهسازی این مدل، میتوانید از کتابخانههایی مانند TensorFlow یا PyTorch استفاده کنید.











