
یادگیری ترکیبی voting


یادگیری ترکیبی Voting
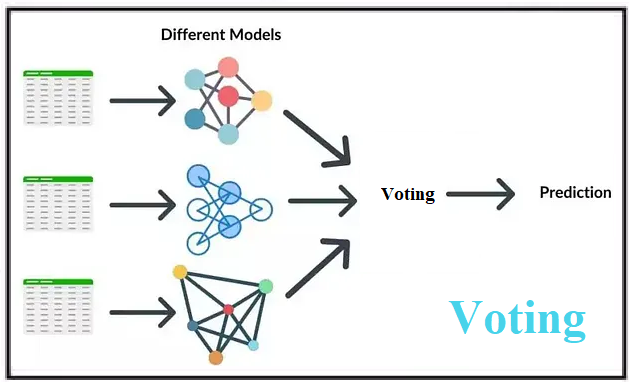
Voting (رأیگیری) یکی دیگر از روشهای یادگیری ترکیبی است که با هدف ترکیب پیشبینیهای چندین مدل پایه (معمولاً مدلهای متفاوت) برای بهبود دقت و پایداری مدل نهایی به کار میرود. این روش در دو نوع اصلی Hard Voting (رأیگیری سخت) و Soft Voting (رأیگیری نرم) پیادهسازی میشود. برخلاف Bagging که از یک نوع مدل پایه (مثل درخت تصمیم) روی زیرمجموعههای مختلف داده استفاده میکند، Voting معمولاً از مدلهای متنوع (مثل درخت تصمیم، SVM، رگرسیون لجستیک) روی کل دادههای آموزشی استفاده میکند و پیشبینیهای آنها را ترکیب میکند.
نحوه کار Voting
ایده اصلی Voting این است که پیشبینیهای چندین مدل پایه مستقل را ترکیب کنیم تا تصمیم نهایی بهتری بگیریم. این روش فرض میکند که ترکیب مدلهای مختلف میتواند ضعفهای هر مدل را جبران کند و دقت کلی را افزایش دهد.
آموزش (Training):
- انتخاب مدلهای پایه: چندین مدل مختلف (مانند درخت تصمیم، SVM، KNN، یا رگرسیون لجستیک) انتخاب میشوند.
- آموزش مستقل: هر مدل به طور جداگانه روی کل مجموعه داده آموزشی (بدون نمونهبرداری تصادفی) آموزش داده میشود.
- عدم تعامل بین مدلها: مدلها به طور مستقل عمل میکنند و هیچ وابستگیای بین آنها وجود ندارد.
- ذخیره مدلها: تمام مدلهای آموزشدیده برای استفاده در مرحله پیشبینی ذخیره میشوند.
تست (Testing) یا پیشبینی:
- پیشبینی توسط هر مدل: برای یک داده جدید (از مجموعه تست یا دادههای واقعی)، هر مدل پایه به طور جداگانه پیشبینی خود را انجام میدهد.
- ترکیب پیشبینیها:
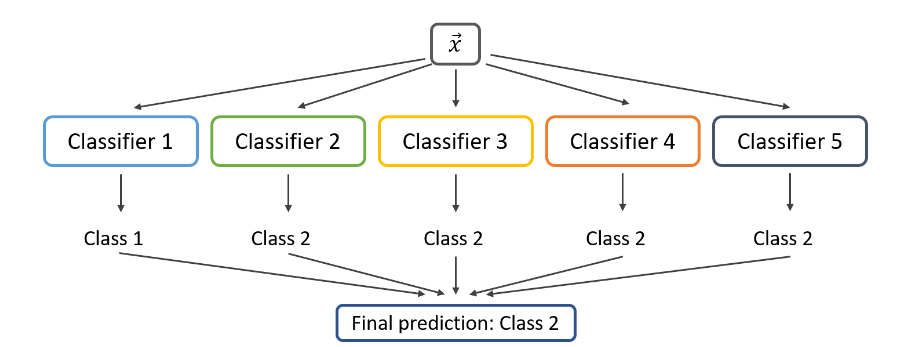
- Hard Voting (رأیگیری سخت): در مسائل طبقهبندی، هر مدل یک کلاس را پیشبینی میکند و کلاسی که بیشترین رأی را از مدلها دریافت کند، به عنوان خروجی نهایی انتخاب میشود.
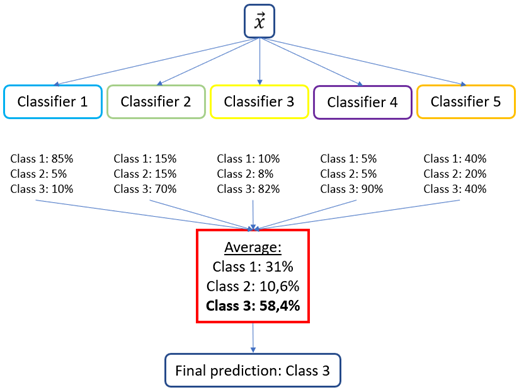
- Soft Voting (رأیگیری نرم): در مسائل طبقهبندی، هر مدل احتمال تعلق به هر کلاس را پیشبینی میکند. سپس میانگین احتمالات برای هر کلاس محاسبه شده و کلاسی با بالاترین احتمال میانگین انتخاب میشود. در مسائل رگرسیون، میانگین پیشبینیهای عددی مدلها گرفته میشود.
- نتیجه نهایی پایدارتر و معمولاً دقیقتر از پیشبینی هر مدل به تنهایی است.
تفاوت رأیگیری سخت (Hard Voting) و رأیگیری نرم (Soft Voting):
1. رأیگیری سخت (Hard Voting)
- در رأیگیری سخت، هر مدل پایه یک کلاس خاص را به عنوان پیشبینی خود ارائه میدهد، و کلاسی که بیشترین تعداد رأی را از مدلهای پایه دریافت کند، به عنوان خروجی نهایی انتخاب میشود. در نهایت از بین پیشبینیهای همه مدلها، کلاسی که بیشترین تعداد رأی را داشته باشد، انتخاب میشود.
- ساده و سریع است، زیرا فقط به پیشبینی کلاسها نیاز دارد. نیازی به محاسبه احتمالات یا وزندهی پیچیده ندارد. برای مدلهایی که خروجی احتمال ندارند (مثل برخی پیادهسازیهای SVM) مناسب است. در نتیجه این مدل رای گیری بیشتر در مسائل طبقهبندی استفاده میشود.
2. رأیگیری نرم (Soft Voting)
- در رأیگیری نرم، هر مدل پایه احتمال تعلق به هر کلاس را پیشبینی میکند، و میانگین احتمالات برای هر کلاس محاسبه میشود. سپس کلاسی که بالاترین میانگین احتمال را داشته باشد، به عنوان خروجی نهایی انتخاب میشود. در این حالت هر مدل پایه (که باید توانایی پیشبینی احتمال را داشته باشد)، برای هر کلاس یک احتمال ارائه میدهد. احتمالات هر کلاس از همه مدلها جمع شده و میانگین گرفته میشود. کلاسی با بالاترین میانگین احتمال به عنوان خروجی انتخاب میشود.
- از اطلاعات اطمینان (confidence) مدلها استفاده میکند، که معمولاً منجر به تصمیمگیری دقیقتر میشود. مدلهایی که اطمینان بیشتری در پیشبینی خود دارند تأثیر بیشتری در نتیجه نهایی دارند. برای مسائل پیچیدهتر با دادههای نویزی مناسبتر است. اما در عوض محاسبات پیچیدهتر از Hard Voting دارد و اگر احتمالات مدلها کالیبره نشده باشند (مثلاً یکی از مدلها احتمالات غیرواقعی تولید کند)، نتیجه ممکن است گمراهکننده باشد.
مزایا
- بهبود دقت: ترکیب مدلهای مختلف میتواند ضعفهای هر مدل را جبران کرده و دقت کلی را افزایش دهد.
- انعطافپذیری: میتوان مدلهای متنوعی (مانند خطی، غیرخطی، یا حتی مدلهای پیچیده) را ترکیب کرد.
- سادگی پیادهسازی: نیازی به تنظیمات پیچیده ندارد و به راحتی با مدلهای مختلف قابل پیادهسازی است.
- مقاوم در برابر نویز: ترکیب پیشبینیهای چندین مدل میتواند اثرات نویز را کاهش دهد.
- موازیسازی آسان: آموزش مدلها میتواند به صورت موازی انجام شود، که سرعت را افزایش میدهد.
معایب
- افزایش هزینه محاسباتی: نیاز به آموزش چندین مدل مختلف، که زمان و منابع بیشتری میطلبد.
- عدم کاهش بایاس: اگر همه مدلهای پایه بایاس بالایی داشته باشند، Voting نمیتواند آن را کاهش دهد.
- پیچیدگی انتخاب مدلها: انتخاب مدلهای مناسب و ترکیب بهینه آنها نیاز به تجربه و آزمایش دارد.
- عدم تفسیرپذیری: مدل نهایی به دلیل ترکیب چندین مدل پیچیدهتر است و درک تصمیمگیری آن دشوارتر میشود.
- وابستگی به مدلهای پایه: اگر مدلهای پایه عملکرد ضعیفی داشته باشند، Voting ممکن است بهبود قابلتوجهی ایجاد نکند.
دادههای مناسب برای روش Voting
روش Voting برای مجموعه دادههایی که ویژگیهای خاصی دارند مناسب است:
- دادههای نویزی: ترکیب مدلهای مختلف میتواند اثر نویز را کاهش دهد، بهویژه در دادههای حسگرها، مالی یا زیستی.
- دادههای پیچیده: برای دادههایی با روابط غیرخطی یا چندبعدی (مثل دادههای متنی، تصویری یا ژنومی)، Voting با ترکیب مدلهای متنوع عملکرد خوبی دارد.
- دادههای دستهای و پیوسته: این روش برای هر دو نوع داده (طبقهبندی و رگرسیون) مناسب است.
- دادههای با اندازه متوسط تا بزرگ: در مجموعههای داده کوچک، ممکن است تنوع مدلها تأثیر زیادی نداشته باشد.
- دادههای نامتوازن: Voting میتواند با ترکیب مدلهایی که برای دادههای نامتوازن تنظیم شدهاند، عملکرد بهتری داشته باشد (مثل استفاده از وزندهی در Soft Voting).
دادههای نامناسب برای روش Voting
- دادههای خیلی کوچک: در مجموعههای داده بسیار کوچک (مثل کمتر از چند صد نمونه)، تنوع مدلها ممکن است تأثیر کمی داشته باشد.
- دادههای با بایاس بالا: اگر مدلهای پایه همگی عملکرد ضعیفی داشته باشند (مثلاً به دلیل دادههای نامناسب یا مدلهای نامناسب)، Voting نمیتواند بهبود چشمگیری ایجاد کند.
- دادههای خیلی ساده: برای دادههایی که روابط سادهای دارند (مثل دادههای خطی که با رگرسیون خطی به خوبی مدل میشوند)، Voting ممکن است پیچیدگی غیرضروری ایجاد کند.
مثال MATLAB و Python
در این مثال، از مجموعه دادههای Iris برای طبقهبندی با روش Voting استفاده میکنیم. از دو ویژگی اول (طول و عرض کاسبرگ) برای سادهسازی استفاده شده و سه مدل پایه (درخت تصمیم، KNN و رگرسیون لجستیک) ترکیب میشوند. خروجی نواحی تصمیمگیری مدل نهایی به صورت بصری نمایش داده میشود.
کد MATLAB
% Load Iris dataset
load fisheriris
X = meas(:, 1:2); % Use first two features: sepal length & sepal width
Y = species;
% Convert species to numeric labels
Y_numeric = grp2idx(Y);
% Define base models
t1 = templateTree('MaxNumSplits', 10); % Decision Tree
t2 = templateKNN('NumNeighbors', 5); % KNN
t3 = templateLinear('Learner', 'logistic'); % Logistic Regression
% Train Voting ensemble
votingModel = fitcensemble(X, Y_numeric, 'Method', 'Bag', ...
'Learners', {t1, t2, t3}, 'NumLearningCycles', 3); % 3 base models
% Create grid for decision boundary
[x1Grid, x2Grid] = meshgrid(linspace(min(X(:,1))-1, max(X(:,1))+1, 100), ...
linspace(min(X(:,2))-1, max(X(:,2))+1, 100));
XGrid = [x1Grid(:), x2Grid(:)];
predictedLabels = predict(votingModel, XGrid);
% Plot
figure;
gscatter(X(:,1), X(:,2), Y_numeric, 'rgb', 'o', 8);
hold on;
contourf(x1Grid, x2Grid, reshape(predictedLabels, size(x1Grid)), ...
'LineColor', 'none', 'FaceAlpha', 0.3);
title('Voting Ensemble on Iris Dataset');
xlabel('Sepal length');
ylabel('Sepal width');
legend('Setosa', 'Versicolor', 'Virginica');
hold off;
کد Python
from sklearn.datasets import load_iris
from sklearn.ensemble import VotingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
import numpy as np
# Load Iris dataset
iris = load_iris()
X = iris.data[:, :2] # Use first two features: sepal length & sepal width
y = iris.target
# Define base models
clf1 = DecisionTreeClassifier(max_depth=10)
clf2 = KNeighborsClassifier(n_neighbors=5)
clf3 = LogisticRegression(max_iter=1000)
# Train Voting classifier (Hard Voting)
model = VotingClassifier(
estimators=[('dt', clf1), ('knn', clf2), ('lr', clf3)],
voting='hard'
)
model.fit(X, y)
# Plot decision boundaries
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.4, cmap=plt.cm.coolwarm)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolor='k', cmap=plt.cm.coolwarm)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('Voting Ensemble on Iris Dataset')
plt.show()
توضیح کد
- دادهها: از مجموعه داده Iris استفاده شده و دو ویژگی اول (طول و عرض کاسبرگ) برای سادهسازی انتخاب شدهاند.
- مدلهای پایه: در MATLAB و Python، سه مدل پایه (درخت تصمیم، KNN، و رگرسیون لجستیک) برای Voting استفاده شدهاند.
- ترکیب: در MATLAB، از روش پیشفرض Ensemble استفاده شده که مشابه Hard Voting عمل میکند. در Python، به صراحت از Hard Voting استفاده شده است.
- نمایش: نواحی تصمیمگیری با استفاده از مشبک (meshgrid) رسم شده و نقاط داده با رنگهای مختلف نمایش داده میشوند.
نکته : برای استفاده از Soft Voting در Python، میتوانید ‘voting=’soft را در voting classifier تنظیم کنید، به شرطی که مدلهای پایه توانایی پیشبینی احتمال (مانند perdic_prob) را داشته باشند. در MATLAB، تنظیم مشابهی نیاز به استفاده از قالبهای خاص یا پیادهسازی دستی دارد. این مثال نشان میدهد که چگونه Voting میتواند با ترکیب مدلهای متنوع، نواحی تصمیمگیری پایدار و دقیقی را برای دادههای Iris ایجاد کند.











