
یادگیری ترکیبی Stacking


یادگیری ترکیبی Stacking
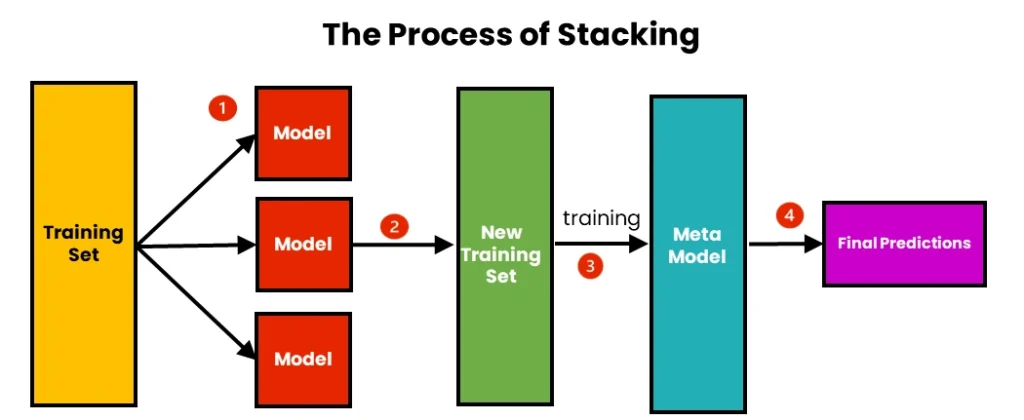
Stacking (یا Stacked Generalization) یکی از روشهای یادگیری ترکیبی است که با هدف بهبود دقت پیشبینی از طریق ترکیب پیشبینیهای چندین مدل پایه (معمولاً مدلهای متنوع مانند درخت تصمیم، SVM، یا شبکههای عصبی) عمل میکند. این روش توسط دیوید ولفورد (David H. Wolpert) در سال ۱۹۹۲ معرفی شد. ایده اصلی Stacking این است که به جای ترکیب ساده پیشبینیها (مانند میانگینگیری در Bagging یا وزندهی در Boosting)، یک مدل سطح بالاتر (متا-مدل) آموزش داده شود تا پیشبینیهای مدلهای پایه را ترکیب کند و نتیجه نهایی را تولید کند. این روش بهویژه برای مسائل پیچیده که مدلهای مختلف نقاط قوت متفاوتی دارند، بسیار مؤثر است.
نحوه آموزش و تست دادهها
آموزش (Training):
۱. تقسیم دادههای آموزشی: دادههای آموزشی به دو بخش تقسیم میشوند: بخش اول برای آموزش مدلهای پایه (Base Learners) و بخش دوم برای آموزش مدل سطح بالاتر (Meta-Learner).
معمولاً از روش اعتبارسنجی متقاطع (Cross-Validation) برای تولید پیشبینیهای مدلهای پایه استفاده میشود تا از بیشبرازش جلوگیری شود.
۲. آموزش مدلهای پایه: چندین مدل پایه متنوع (مانند درخت تصمیم، KNN، SVM، یا رگرسیون لجستیک) روی بخش اول دادههای آموزشی آموزش داده میشوند. هر مدل پایه پیشبینیهایی (برای مسائل طبقهبندی: احتمال کلاسها، برای رگرسیون: مقادیر عددی) تولید میکند.
۳. ایجاد دادههای متا: پیشبینیهای مدلهای پایه (از اعتبارسنجی متقاطع یا دادههای بخش دوم) به عنوان ویژگیهای ورودی برای مدل متا-لرنر استفاده میشوند. برچسبهای واقعی (Ground Truth) برای این دادهها حفظ میشوند.
۴. آموزش مدل متا: یک مدل سطح بالاتر (مانند رگرسیون لجستیک، شبکه عصبی، یا حتی یک درخت تصمیم) روی دادههای متا (پیشبینیهای مدلهای پایه) آموزش داده میشود تا یاد بگیرد چگونه پیشبینیهای مدلهای پایه را ترکیب کند.
۵. ترکیب نهایی: مدل متا تصمیم نهایی را بر اساس پیشبینیهای مدلهای پایه تولید میکند.
تست (Testing) یا پیشبینی:
۱. برای یک داده جدید (از مجموعه تست یا دادههای واقعی)، ابتدا هر مدل پایه پیشبینی خود را تولید میکند.
۲. پیشبینیهای مدلهای پایه به عنوان ورودی به مدل متا داده میشود.
۳. مدل متا پیشبینی نهایی را تولید میکند:
- در مسائل طبقهبندی (Classification): معمولاً یک کلاس یا احتمال کلاسها خروجی داده میشود.
- در مسائل رگرسیون (Regression): یک مقدار عددی به عنوان خروجی نهایی محاسبه میشود.
این فرآیند باعث میشود Stacking بتواند از نقاط قوت مدلهای مختلف بهره ببرد و پیشبینیهای دقیقتری نسبت به هر مدل پایه به تنهایی ارائه دهد.
مزایا
- بهرهگیری از تنوع مدلها: Stacking میتواند از مدلهای پایه متنوع (مانند الگوریتمهای خطی و غیرخطی) استفاده کند و نقاط قوت آنها را ترکیب کند.
- دقت بالا: به دلیل استفاده از مدل متا برای ترکیب هوشمند پیشبینیها، معمولاً دقت بیشتری نسبت به Bagging یا Boosting در مسائل پیچیده دارد.
- انعطافپذیری: میتوان از هر نوع مدل پایه و متا استفاده کرد، که این روش را برای مسائل مختلف مناسب میکند.
- کاهش بایاس و واریانس: با ترکیب مدلهای متنوع، Stacking میتواند هم بایاس و هم واریانس را کاهش دهد.
- مناسب برای مسائل رقابتی: Stacking به دلیل توانایی ترکیب مدلهای قوی، در مسابقات یادگیری ماشین (مانند Kaggle) بسیار محبوب است.
معایب
- پیچیدگی محاسباتی: نیاز به آموزش چندین مدل پایه و یک مدل متا، همچنین استفاده از اعتبارسنجی متقاطع، هزینه محاسباتی بالایی دارد.
- پیچیدگی پیادهسازی: نسبت به Bagging و Boosting، پیادهسازی Stacking پیچیدهتر است و نیاز به تنظیم دقیق دارد.
- خطر بیشبرازش: اگر اعتبارسنجی متقاطع به درستی انجام نشود یا مدل متا بیش از حد پیچیده باشد، ممکن است بیشبرازش رخ دهد.
- عدم تفسیرپذیری: مدل نهایی به دلیل ترکیب چندین مدل پیچیده، تفسیر آن دشوار است.
- نیاز به دادههای کافی: برای عملکرد خوب، نیاز به دادههای کافی برای آموزش مدلهای پایه و متا دارد.
دادههای مناسب برای روش Stacking
روش Stacking بهطور کلی برای مجموعه دادههایی با ویژگیهای زیر مناسب است:
- دادههای پیچیده با الگوهای متنوع: Stacking در دادههایی که الگوهای مختلفی (خطی و غیرخطی) دارند (مانند دادههای مالی، تصویر، یا متنی) بسیار مؤثر است.
- دادههای با حجم متوسط تا بزرگ: برای آموزش مدلهای پایه و متا، نیاز به دادههای کافی است تا از بیشبرازش جلوگیری شود.
- دادههای چندبعدی: در دادههایی با ویژگیهای زیاد (مانند دادههای ژنومی یا دادههای حسگر) عملکرد خوبی دارد.
- دادههای نامتوازن: با ترکیب مدلهای متنوع، Stacking میتواند با مسائل نامتوازن بهخوبی کنار بیاید.
- دادههایی که مدلهای مختلف عملکرد متفاوتی دارند: اگر مدلهای پایه نقاط قوت و ضعف متفاوتی داشته باشند، Stacking میتواند بهترین ترکیب را پیدا کند.
دادههای نامناسب برای روش Stacking
- دادههای خیلی کوچک: اگر مجموعه داده خیلی کوچک باشد (مثلاً کمتر از چند صد نمونه)، آموزش مدلهای پایه و متا ممکن است ناکارآمد باشد.
- دادههای ساده: اگر روابط در دادهها خطی یا ساده باشند (مانند دادههایی که با رگرسیون خطی به خوبی مدل میشوند)، Stacking ممکن است پیچیدگی غیرضروری ایجاد کند.
- دادههای بسیار نویزی: اگر دادهها نویز زیادی داشته باشند، مدلهای پایه ممکن است پیشبینیهای نادرستی تولید کنند که مدل متا را گمراه میکند.
- دادههایی که نیاز به تفسیرپذیری دارند: به دلیل پیچیدگی مدل نهایی، Stacking برای کاربردهایی که نیاز به تفسیر آسان دارند مناسب نیست.
مثال MATLAB و Python
در زیر یک مثال MATLAB برای طبقهبندی مجموعه داده Iris با استفاده از روش Stacking ارائه شده است. ابتدا دادههای Iris بارگذاری شده و دو ویژگی اول (طول و عرض کاسبرگ) انتخاب میشوند. دادهها با نسبت 70% آموزش و 30% تست تقسیم شده و برچسبهای رشتهای به عددی تبدیل میشوند. دو مدل پایه (درخت تصمیم با عمق 3 و KNN با 5 همسایه) روی دادههای آموزشی آموزش داده میشوند و پیشبینیهای آنها با اعتبارسنجی متقاطع 5-Fold به عنوان ویژگیهای ورودی برای مدل متا (رگرسیون لجستیک) تولید میشود. مدل متا روی این پیشبینیها آموزش داده شده و برای پیشبینی دادههای تست استفاده میشود. در نهایت، دقت مدل محاسبه شده و نواحی تصمیمگیری با استفاده از meshgrid و contourf به صورت بصری نمایش داده میشود، همراه با نقاط داده که با gscatter رسم شدهاند.
% بارگذاری مجموعه داده Iris
load fisheriris;
X = meas(:, 1:2); % فقط دو ویژگی اول (طول و عرض کاسبرگ)
y = species; % برچسبهای کلاس
% تبدیل برچسبهای رشتهای به عددی
[~, ~, y_numeric] = unique(y);
% تقسیم دادهها به آموزش و تست
rng(42); % برای تکرارپذیری
cv = cvpartition(length(y), 'HoldOut', 0.3); % 30% برای تست
X_train = X(cv.training, :);
y_train = y_numeric(cv.training);
X_test = X(cv.test, :);
y_test = y_numeric(cv.test);
% آموزش مدلهای پایه
base_model1 = fitctree(X_train, y_train, 'MaxDepth', 3); % درخت تصمیم
base_model2 = fitcknn(X_train, y_train, 'NumNeighbors', 5); % KNN
% تولید پیشبینیهای مدلهای پایه با اعتبارسنجی متقاطع
cv_model = crossvalind('Kfold', size(X_train, 1), 5); % 5-Fold Cross-Validation
meta_features = zeros(size(X_train, 1), 2); % برای ذخیره پیشبینیهای مدلهای پایه
for k = 1:5
train_idx = cv_model ~= k;
test_idx = cv_model == k;
% آموزش مدلهای پایه روی دادههای Fold
temp_model1 = fitctree(X_train(train_idx, :), y_train(train_idx), 'MaxDepth', 3);
temp_model2 = fitcknn(X_train(train_idx, :), y_train(train_idx), 'NumNeighbors', 5);
% پیشبینی برای دادههای تست Fold
meta_features(test_idx, 1) = predict(temp_model1, X_train(test_idx, :));
meta_features(test_idx, 2) = predict(temp_model2, X_train(test_idx, :));
end
% آموزش مدل متا (رگرسیون لجستیک)
meta_model = fitcecoc(meta_features, y_train); % مدل متا با رگرسیون لجستیک
% تولید پیشبینیهای مدلهای پایه برای دادههای تست
test_meta_features = [predict(base_model1, X_test), predict(base_model2, X_test)];
% پیشبینی نهایی با مدل متا
y_pred = predict(meta_model, test_meta_features);
% ارزیابی دقت مدل
accuracy = sum(y_pred == y_test) / length(y_test);
fprintf('دقت مدل Stacking: %.2f\n', accuracy);
% رسم نواحی تصمیمگیری
x_min = min(X(:,1)) - 1; x_max = max(X(:,1)) + 1;
y_min = min(X(:,2)) - 1; y_max = max(X(:,2)) + 1;
[xx, yy] = meshgrid(x_min:0.01:x_max, y_min:0.01:y_max);
X_grid = [xx(:), yy(:)];
% پیشبینی مدلهای پایه برای نواحی تصمیمگیری
grid_meta_features = [predict(base_model1, X_grid), predict(base_model2, X_grid)];
% پیشبینی نهایی برای نواحی تصمیمگیری
Z = predict(meta_model, grid_meta_features);
Z = reshape(Z, size(xx));
% رسم نواحی تصمیمگیری و نقاط داده
figure;
contourf(xx, yy, Z, 'LineStyle', 'none');
colormap([1 0.7 0.7; 0.7 1 0.7; 0.7 0.7 1]); % رنگهای متمایز
hold on;
gscatter(X(:,1), X(:,2), y, 'rbg', 'o', 5, 'filled'); % نقاط داده
xlabel('طول کاسبرگ (cm)');
ylabel('عرض کاسبرگ (cm)');
title('نواحی تصمیمگیری مدل Stacking (Iris)');
legend('Location', 'best');
hold off;
در کد Python از روش Stacking برای طبقهبندی مجموعه داده Iris استفاده میکند. ابتدا دادههای Iris با تابع load_iris از کتابخانه sklearn.datasets بارگذاری شده و دو ویژگی اول (طول و عرض کاسبرگ) انتخاب میشوند. دادهها با تابع train_test_split به نسبت 70% آموزش و 30% تست تقسیم میشوند. دو مدل پایه، شامل درخت تصمیم (DecisionTreeClassifier با max_depth=3) و KNN (KNeighborsClassifier با n_neighbors=5)، با تابع fit روی دادههای آموزشی آموزش داده میشوند. پیشبینیهای این مدلها با تابع cross_val_predict و اعتبارسنجی متقاطع 5-Fold به عنوان ویژگیهای ورودی برای مدل متا تولید میشود. مدل متا، که یک رگرسیون لجستیک (LogisticRegression با multi_class=’multinomial’) است، با تابع fit روی این پیشبینیها آموزش داده شده و با تابع predict برای پیشبینی دادههای تست استفاده میشود. دقت مدل با مقایسه پیشبینیها و برچسبهای واقعی محاسبه شده و نواحی تصمیمگیری با توابع meshgrid از numpy و contourf و scatter از matplotlib.pyplot به صورت بصری نمایش داده میشود.
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_predict
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
# بارگذاری مجموعه داده Iris
iris = load_iris()
X = iris.data[:, :2] # فقط دو ویژگی اول (طول و عرض کاسبرگ)
y = iris.target
# تقسیم دادهها به آموزش و تست
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# آموزش مدلهای پایه
base_model1 = DecisionTreeClassifier(max_depth=3, random_state=42) # درخت تصمیم
base_model2 = KNeighborsClassifier(n_neighbors=5) # KNN
# تولید پیشبینیهای مدلهای پایه با اعتبارسنجی متقاطع
meta_features = np.column_stack([
cross_val_predict(base_model1, X_train, y_train, cv=5, method='predict'),
cross_val_predict(base_model2, X_train, y_train, cv=5, method='predict')
])
# آموزش مدلهای پایه روی کل دادههای آموزشی
base_model1.fit(X_train, y_train)
base_model2.fit(X_train, y_train)
# آموزش مدل متا (رگرسیون لجستیک)
meta_model = LogisticRegression(multi_class='multinomial', random_state=42)
meta_model.fit(meta_features, y_train)
# تولید پیشبینیهای مدلهای پایه برای دادههای تست
test_meta_features = np.column_stack([
base_model1.predict(X_test),
base_model2.predict(X_test)
])
# پیشبینی نهایی با مدل متا
y_pred = meta_model.predict(test_meta_features)
# ارزیابی دقت مدل
accuracy = np.mean(y_pred == y_test)
print(f"دقت مدل Stacking: {accuracy:.2f}")
# رسم نواحی تصمیمگیری
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))
X_grid = np.c_[xx.ravel(), yy.ravel()]
# پیشبینی مدلهای پایه برای نواحی تصمیمگیری
grid_meta_features = np.column_stack([
base_model1.predict(X_grid),
base_model2.predict(X_grid)
])
# پیشبینی نهایی برای نواحی تصمیمگیری
Z = meta_model.predict(grid_meta_features)
Z = Z.reshape(xx.shape)
# رسم نواحی تصمیمگیری و نقاط داده
plt.figure(figsize=(10, 6))
cmap = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
plt.contourf(xx, yy, Z, cmap=cmap, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap, edgecolors='k', s=100)
plt.xlabel('طول کاسبرگ (cm)')
plt.ylabel('عرض کاسبرگ (cm)')
plt.title('نواحی تصمیمگیری مدل Stacking (Iris)')
plt.show()











