
راهنمای سریع شبکه عصبی بازگشتی (RNN)


شبکه عصبی بازگشتی (RNN) گونهای از شبکههای عصبی مصنوعی است که برای تحلیل توالیهای زمانی و دادههای متوالی طراحی شده است. برخلاف شبکههای پیشخور، این معماری شامل اتصالاتی فیدبکی است که به آن امکان میدهد وضعیت داخلی یا «حالت پنهان» را از یک گام زمانی به گام بعد منتقل کند و از این طریق، اطلاعات مربوط به ورودیهای گذشته را نیز در فرایند تصمیمگیری دخیل کند.
به واسطه این ویژگی، RNNها در کاربردهایی چون پردازش زبان طبیعی، تشخیص گفتار، پیشبینی سریهای زمانی و تحلیل سیگنالهای وابسته به زمان، عملکرد برجستهای از خود نشان میدهند.
معماری RNN سنتی
شاخص اصلی در شبکههای عصبی بازگشتی (RNN) این است که خروجیهای قبلی به عنوان ورودی های لایه بعدی استفاده میشود و مفهوم حالتهای پنهان (hidden states) در این شبکه ها ارایه می شود. فرم اولیه شبکه های بازگشتی به صورت زیر است:
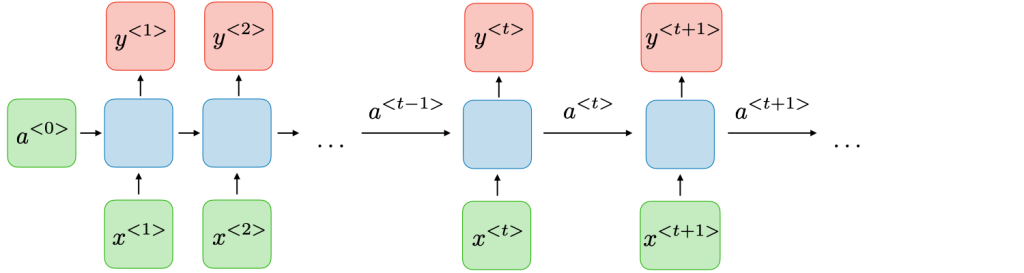
در یک شبکه بازگشتی، در هر لحظه زمانی t، حالت پنهان a( t) از ترکیب حالت پنهان لحظه قبل a( t-1) و ورودی جدید خروجی x( t) تشکیل میشود، و خروجی y(t) از آن استخراج میگردد:
که در آن Wax, Waa, Wya, ba, by ضرایب مشترکی هستند که در طول زمان به اشتراک گذاشته میشوند وg1, g2 توابع فعالسازی می باشند.شکل باز شده هر سلول به صورت زیر است:
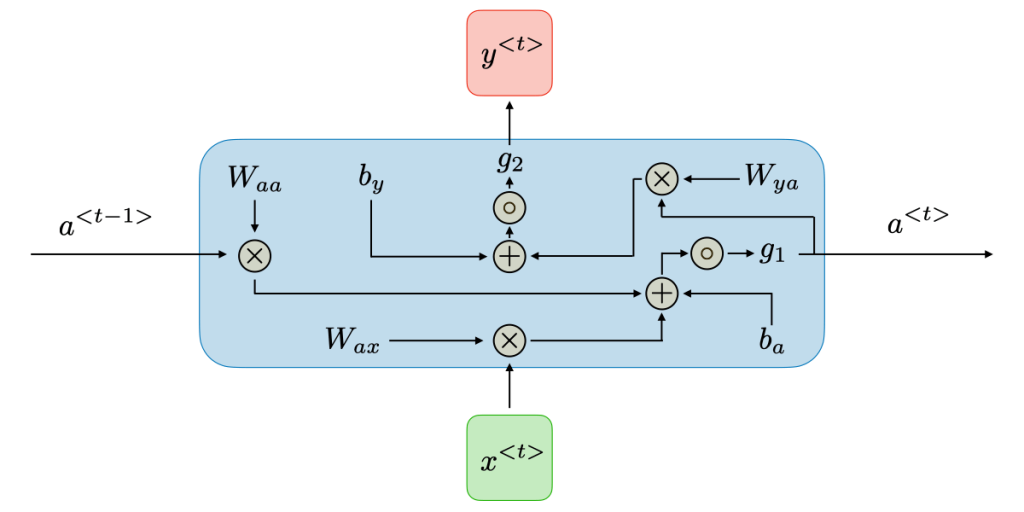
RNN را مشابه یک زنجیره تصور کنید که هر واحد (سلول) ورودی فعلی (t)x رو با حافظه قبلی (1-t)a ترکیب کرده، از تابع فعالسازی (مثل tanh) رد میکنه و حافظه جدید (t)a میسازد. این حافظه هم در تولید خروجی موثر است و هم به گام بعدی منتقل میشود. مثل نوار نقالهای که اطلاعات را جلو هدایت می کند!
این ساختار سبب میشود که مدل بتواند وابستگی میان مراحل متوالی دادهها را بیاموزد و از آن برای پیشبینی یا تولید بهره گیرد. فرایند آموزش معمولاً با «بازگشت به عقب از طریق زمان» (Back‑Propagation Through Time | BPTT) انجام میپذیرد، یعنی مشتق تابع هزینه به ازای کل توالی زمانی نسبت به پارامترهای آموزشی محاسبه میشود:
و تابع هزینه نیز برای همه خروجیهای گامهای زمانی به صورت زیر تعریف میشود:
مزایا و معایب RNN معمولی
مزایا و معایب یک معماری RNN معمولی رو در جدول زیر خلاصه کردیم:
| مزایا | معایب |
|---|---|
| ۱. قابلیت کار با توالیهای داده با طول متغیر که در بسیاری از کاربردها نظیر متن، گفتار یا حسگرهای زمانی دیده میشود. ۲. امکان حفظ وضعیت یا حافظه کوتاهمدت از ورودیهای گذشته و دخیل کردن آن در تصمیمگیریهای جاری، که توانایی تحلیل زمینه را برای مدل فراهم میآورد. | 1. RNNهای اولیه با مشکلاتی در یادگیری وابستگیهای بلندمدت مواجه هستند؛ یکی از مهمترین آنها «محو شدن گرادیان» (Vanishing Gradient) است که مانع از بهروزرسانی مؤثر وزنها برای مراحل زمانی دیرتر میشود. 2. «انفجار گرادیان» (Exploding Gradient) است که با مقادیر بسیار بزرگ گرادیان موجب ناپایداری فرایند آموزش میشود. |
شبکه را مثل یک زنجیره طولانی تصور کنید و در فرایند آموزش گرادیانها از آخر به اول منتقل می شود. ممکن است روند آموزش دچار محو شدگی گرادیانها (vanishing) یا انفجار گرادیان (exploding) شوند که این مساله در LSTM حل شده است.
کاربردهای RNN
مدلهای RNN بیشتر در زمینههای پردازش زبان طبیعی (NLP) و تشخیص گفتار استفاده میشد. کاربردهای مختلف در جدول زیر با مثال آورده شده است:
| نوع RNN | نمایش شبکه | مثال |
|---|---|---|
| One-to-one Tx=Ty=1 | یک شبکه عصبی سنتی ساده: 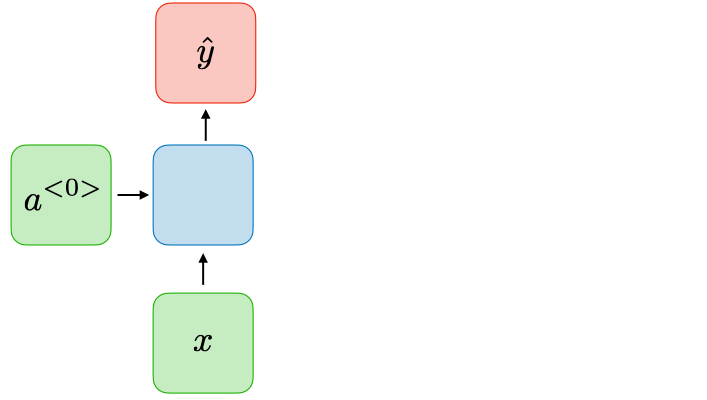 | شبکه عصبی سنتی |
| One-to-many Tx=1, Ty>1 | ورودی واحد به خروجیهای متعدد: 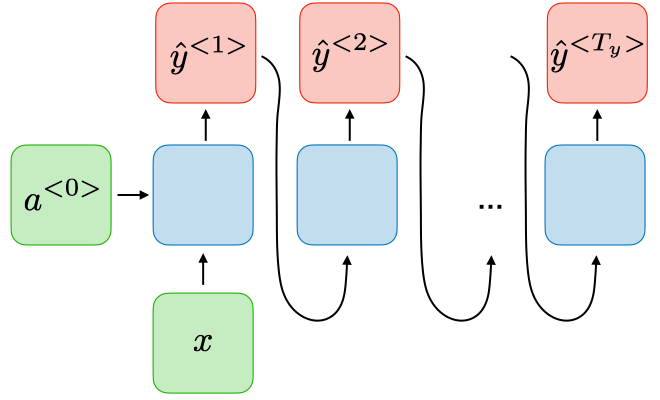 | تولید موسیقی از نت اولیه |
| Many-to-one Tx>1, Ty=1 | ورودیهای متعدد به خروجی واحد: 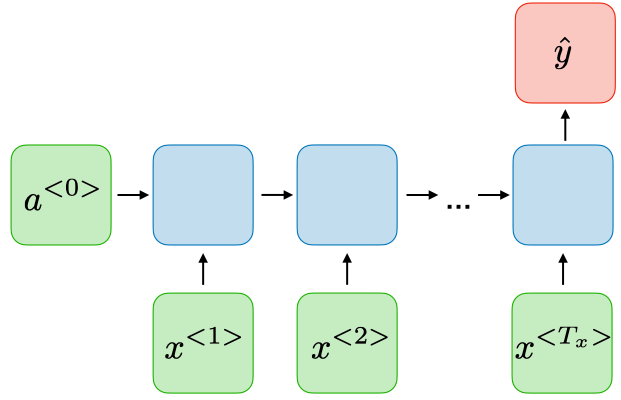 | طبقهبندی احساسات از یک جمله کامل. |
| Many-to-many 1<Tx=Ty | ورودی و خروجی با طول برابر: 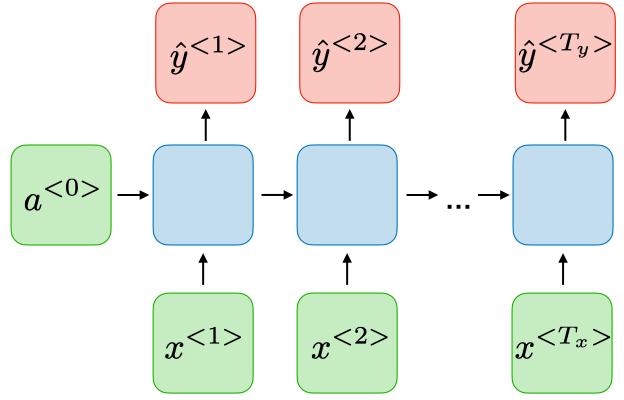 | شناسایی نام اشخاص در متن |
| Many-to-many Tx=/=Ty | ورودی و خروجی با طول نابرابر: 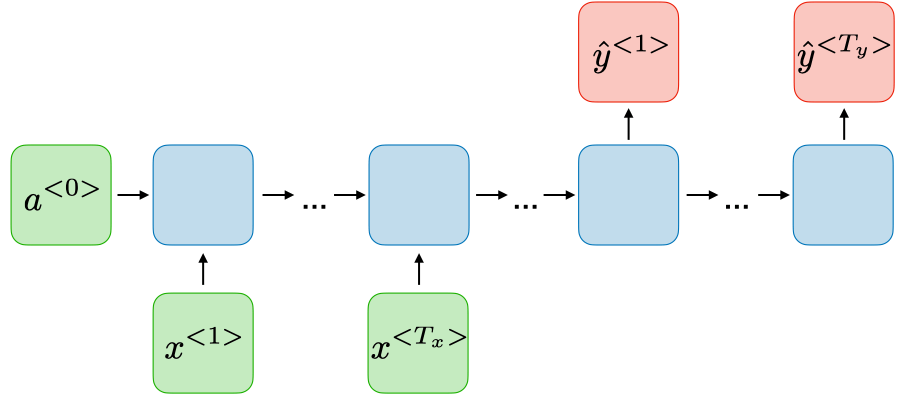 | مثل ترجمه ماشین که جملات طولهای متفاوت دارن. |
Tx طول ورودی و Ty طول خروجی است.
توابع فعالسازی رایج
در جدول زیر، مهمترین توابع فعالسازی مورد استفاده در ماژولهای RNN آورده شدهاند:
| تابع | فرمول ریاضی | نمودار و کاربرد |
|---|---|---|
| Sigmoid | 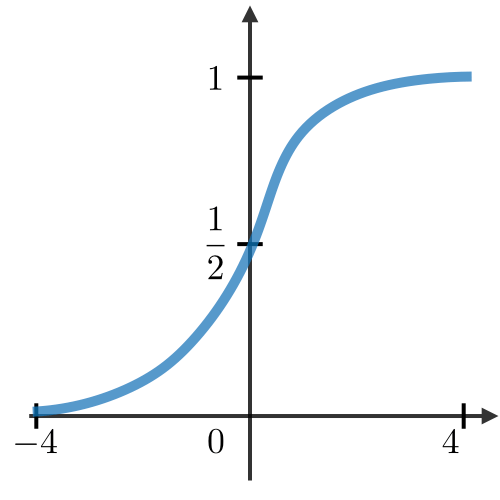 | منحنی S شکل بین ۰ تا ۱ – مناسب برای گیتها |
| Tanh | 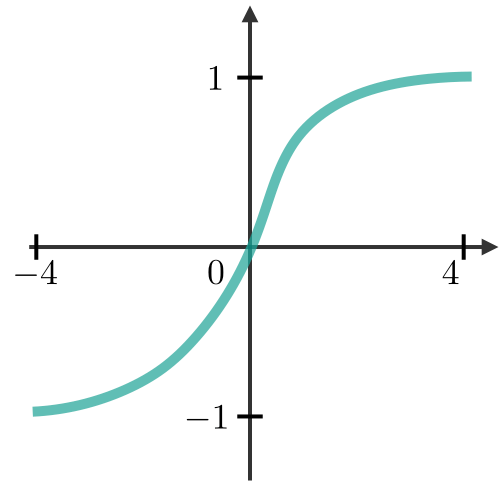 | منحنی S شکل بین -۱ تا ۱ – رایج در حافظه RNN |
| ReLU | 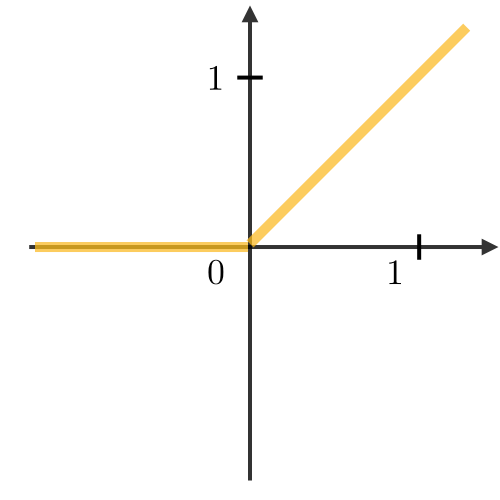 | خطی از صفر به بالا – سریع ولی گاهی “مرده” |
- تابع Tanh خروجی را در بازه [-1, 1] نگه میدارد که به تعادل سیگنال کمک میکند.
- ReLU سریعتر است اما برای مقادیر منفی ممکن است فعال نشود (مشکل نرون مرده).
- Sigmoid بیشتر برای گیتها کاربرد دارد چون خروجی آن در بازه [0, 1] است و حالت “روشن/خاموش” را شبیهسازی میکند.
انواع دیگر RNN
جدول زیر، مقایسهای ساده و کاربردی بین دو نوع پرکاربرد از شبکههای بازگشتی (RNN)، یعنی مدلهای دوجهته (BRNN) و عمیق (DRNN)، ارائه میدهد.
| ویژگی | BRNN (شبکه بازگشتی دوجهته) | DRNN (شبکه بازگشتی عمیق) |
|---|---|---|
| نوع پردازش زمانی | پردازش از دو جهت: گذشته و آینده (چپ به راست و راست به چپ) | پردازش در یک جهت، اما با چندین لایه بازگشتی رویهم |
| هدف اصلی | استفاده همزمان از اطلاعات قبل و بعد برای درک بهتر دنباله | یادگیری ویژگیهای پیچیدهتر با افزایش عمق مدل |
| مناسب برای | ترجمه ماشینی، تحلیل احساسات، برچسبگذاری توالی (NER، POS tagging) | تشخیص گفتار، پیشبینی سریهای زمانی پیچیده، درک ساختارهای عمیقتر |
| محدودیت | نیاز به دانستن کل دنباله → مناسب فقط برای دادههای غیر بلادرنگ | ممکن است با مشکل محو شدگی گرادیان مواجه شود |
| نمای شبکه | 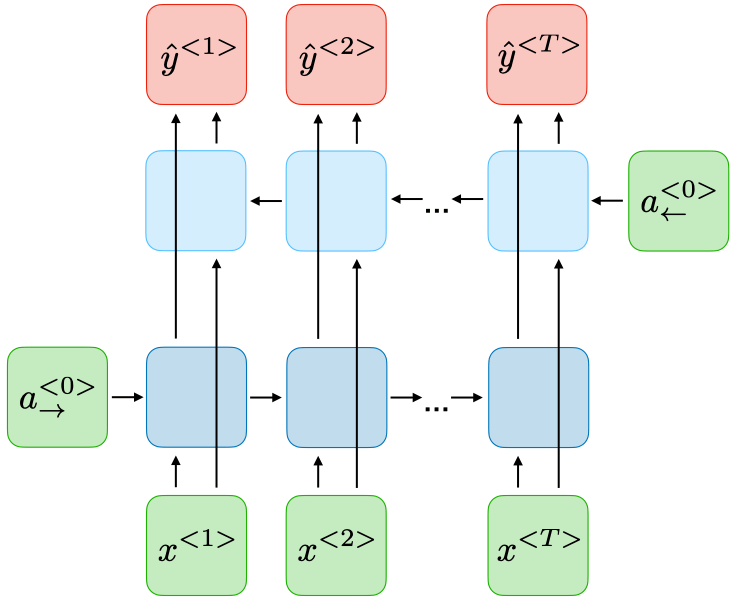 | 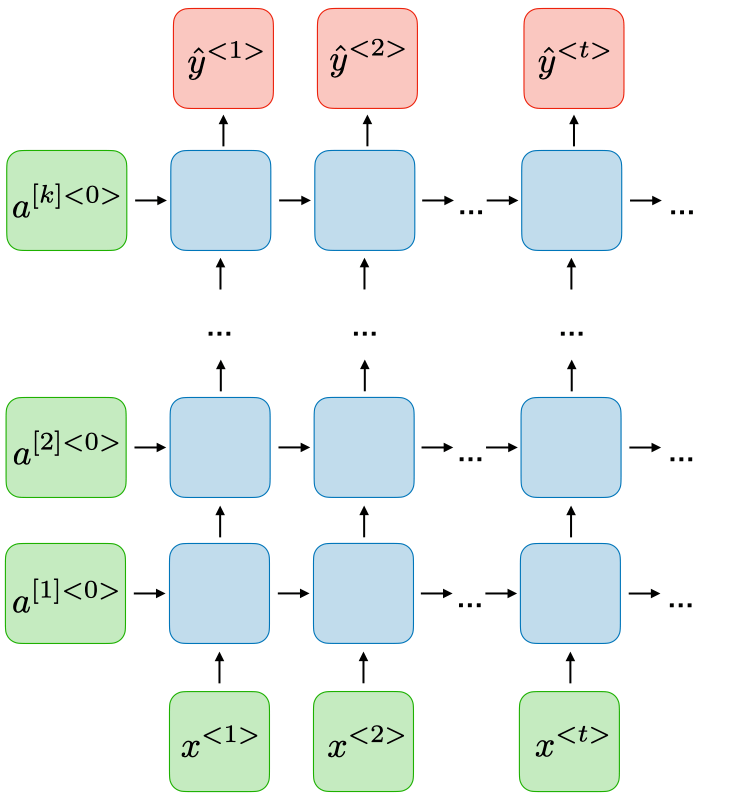 |
هر دو معماری افزونهای بر معماری پایه RNN هستند، یعنی همان مفهوم کلی «پردازش دادههای دنبالهای / زمانی با استفاده از حالت مخفی» را دارند. تفاوت بزرگ این است که BRNN جهت زمانی را گسترش میدهد (به گذشته و آینده نگاه میکند)، و DRNN عمق لایهها را افزایش میدهد (به لایههای متعدد نیاز دارد).
مدیریت وابستگیهای بلندمدت (Handling Long-Term Dependencies)
مدلهای RNN در تئوری میتوانند وابستگیهای زمانی طولانی را یاد بگیرند. با این حال، در عمل با مشکلاتی نظیر محو شدگی گرادیان و انفجار گرادیان روبهرو هستند. این پدیدهها باعث میشوند مدل در یادگیری روابط بین دادههای دورتر در دنباله عملکرد ضعیفی داشته باشد.
به همین دلیل، معماریهای پیشرفتهتری مانند LSTM و GRU معرفی شدند تا بتوانند وابستگیهای بلندمدت را به شکلی مؤثرتر مدیریت کنند. در مقالات اینده این دو مدل از یادگیری بازگشتی را مورد بررسی قرار می دهیم.











