
روش های انتخاب ویژگی

مقدمه
در پروژههای یادگیری ماشین، دادهها معمولاً شامل تعداد زیادی ویژگی (Feature) هستند، اما همهی آنها برای مدل مفید نیستند. برخی ویژگیها بیارتباط، تکراری یا نویزی هستند و میتوانند دقت مدل را کاهش دهند، پیچیدگی را افزایش دهند و کارایی را پایین بیاورند.
انتخاب ویژگی (Feature Selection) فرآیندی است که هدف آن شناسایی و نگهداری مهمترین و مرتبطترین ویژگیها و حذف ویژگیهای غیرضروری است. این کار باعث بهبود عملکرد مدل، کاهش پیچیدگی و افزایش کارایی میشود.
چرا انتخاب ویژگی اهمیت دارد؟
- افزایش سرعت آموزش مدل: کاهش تعداد ویژگیها زمان آموزش مدل را کاهش میدهد.
- بهبود دقت و تعمیمپذیری: حذف ویژگیهای نویزی باعث عملکرد بهتر مدل روی دادههای جدید میشود.
- سادگی و تفسیرپذیری مدل: مدلهای با ویژگیهای کمتر سادهتر و قابلفهمتر هستند.
- کاهش هزینه محاسبات و ذخیرهسازی: این موضوع بهویژه در دادههای بزرگ (Big Data) اهمیت دارد.
انواع روشهای انتخاب ویژگی
روشهای انتخاب ویژگی به طور کلی به سه دسته اصلی تقسیم میشوند که در ادامه توضیح داده شدهاند:
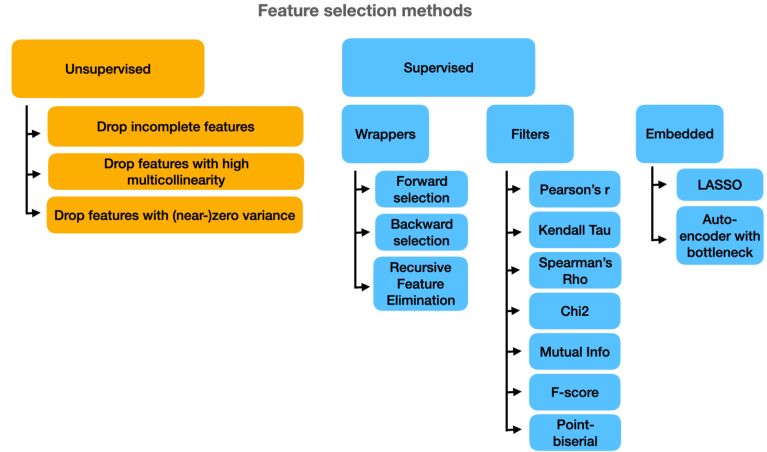
۱. روشهای با ناظر (Supervised Feature Selection)
این روشها زمانی استفاده میشوند که دادهها دارای برچسب هدف (مانند کلاسها در مسائل طبقهبندی یا مقادیر عددی در رگرسیون) باشند. هدف، انتخاب ویژگیهایی است که بیشترین ارتباط را با برچسب هدف دارند.
- آزمون کایدو (Chi-Square Test): بررسی رابطه معنادار بین ویژگیهای گسسته و برچسب هدف.
- آزمون F آنووا (ANOVA F-test): ارزیابی ویژگیهای پیوسته برای بررسی تفاوت معنادار بین گروهها.
- اطلاعات متقابل (Mutual Information): اندازهگیری وابستگی متقابل بین ویژگیها و برچسب هدف.
- mRMR (Minimum Redundancy Maximum Relevance): انتخاب ویژگیهایی با حداکثر ارتباط با هدف و حداقل همبستگی با یکدیگر.
- روشهای مبتنی بر مدل: استفاده از اهمیت ویژگی در مدلهایی مانند جنگل تصادفی (Random Forest) یا ضرایب رگرسیون لاسو (Lasso).
مزایا این روش های این است که استفاده از اطلاعات برچسب باعث انتخاب ویژگیهای دقیقتر و مرتبطتر با هدف میشود.این مدل انتخاب ویژگی در مسائل طبقهبندی (Classification) و رگرسیون (Regression) با دادههای برچسبدارپر کاربرد است.
۲. روشهای بیناظر (Unsupervised Feature Selection)
این روشها برای دادههای بدون برچسب هدف (مانند خوشهبندی) استفاده میشوند و انتخاب ویژگیها بر اساس ویژگیهای درونی دادهها مانند واریانس یا همبستگی انجام میشود.
- حذف ویژگیهای با واریانس پایین: ویژگیهایی که تغییرات کمی دارند، اطلاعات مفیدی ارائه نمیدهند و حذف میشوند.
- تحلیل همبستگی: حذف ویژگیهایی با همبستگی بالا برای کاهش افزونگی.
- روشهای مبتنی بر خوشهبندی: انتخاب ویژگیهایی که به خوشهبندی بهتر کمک میکنند.
چون این روش ها نیازی به برچسب ندارد و برای دادههای بدون ساختار یا بدون برچسب مناسب است، بنابراین در خوشهبندی (Clustering) یا تحلیل دادههای اکتشافی مناسب می شد.
۳. روشهای نیمهناظر (Semi-supervised Feature Selection)
این روشها زمانی استفاده میشوند که بخشی از دادهها برچسبدار و بخشی بدون برچسب هستند. این روشها ترکیبی از تکنیکهای با ناظر و بیناظر را به کار میگیرند.
- Co-training: استفاده از دادههای برچسبدار و بدون برچسب برای بهبود انتخاب ویژگی.
- روشهای مبتنی بر گراف: استفاده از ساختار گرافی دادهها برای شناسایی ویژگیهای مهم.
- روشهای ترکیبی: ترکیب معیارهایی مانند اطلاعات متقابل (برای دادههای برچسبدار) و تحلیل واریانس (برای دادههای بدون برچسب).
این مدل انتخاب ویژگی در سناریوهایی که برچسبگذاری کامل دادهها هزینهبر یا غیرممکن است، بسیار کاربردی است. مسائل واقعی مثل تحلیل دادههای پزشکی، تشخیص بیماریها، یا تحلیل متن که بخشی از دادهها برچسبدار هستند، استفاده از این تکنیک مناسب می باشد.
دستهبندیهای دیگر روشهای انتخاب ویژگی
علاوه بر تقسیمبندی بر اساس وجود یا نبود برچسب، روشهای انتخاب ویژگی را میتوان بر اساس رویکرد نیز به چهار دسته تقسیم کرد:
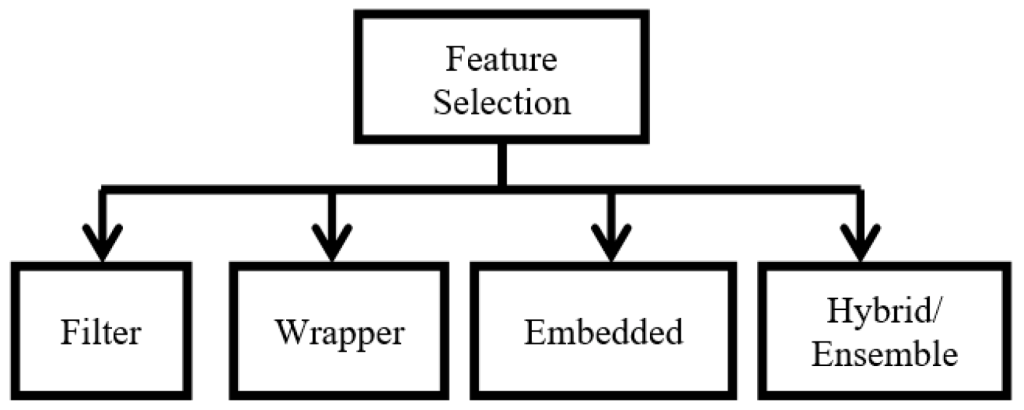
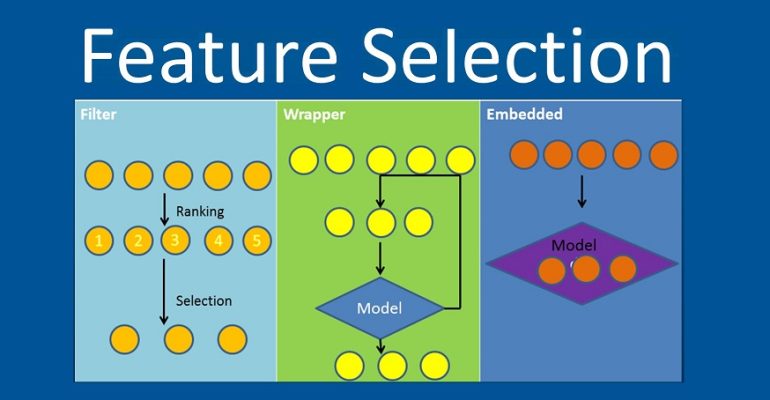
- Filter Methods (روشهای فیلتر) :مستقل از مدل یادگیری ماشین، ویژگیها را بر اساس معیارهای آماری (مثل واریانس، همبستگی، یا Mutual Information) انتخاب میکنند.
- Wrapper Methods (روشهای بستهبندی): ز یک مدل یادگیری ماشین برای ارزیابی زیرمجموعههای ویژگیها استفاده میکنند.
- Embedded Methods (روشهای درونمدلی) :انتخاب ویژگی به طور همزمان با فرآیند یادگیری مدل انجام میشود.
- Hybrid / Advanced Methods (روشهای ترکیبی و پیشرفته)
در ادامه هر کدام را با جزئیات بررسی میکنیم
Filter Methods (مبتنی بر فیلترها)
روشهای فیلتر بدون درگیر کردن هیچ مدل یادگیری، صرفاً با تحلیل آماری دادهها، ویژگیهای مهم را انتخاب میکنند. این روشها سریع، ساده و مناسب برای انتخاب اولیه ویژگیها هستند.

| روش | توضیح | مزایا | معایب |
|---|---|---|---|
| Fisher Score | نسبت واریانس بینکلاسی به درونکلاسی را میسنجد. ویژگیهایی که کلاسها را بهتر از هم جدا کنند امتیاز بالاتری میگیرند. | بسیار سریع و کارآمد در دادههای طبقهبندی | فرض نرمال بودن داده |
| Chi-Square (کای-دو) | میزان وابستگی بین ویژگی و برچسب هدف را بررسی میکند. | مناسب برای ویژگیهای گسسته | برای دادههای عددی مناسب نیست |
| Mutual Information (اطلاعات متقابل) | مقدار اطلاعات مشترک بین ویژگی و خروجی را اندازه میگیرد. | کاربردی در دادههای غیرخطی | پیچیدگی محاسباتی بالا |
| ANOVA F-test | تفاوت میانگین ویژگیها بین کلاسها را بررسی میکند. | مؤثر برای دادههای نرمال | حساس به دادههای غیرنرمال |
| Correlation (همبستگی) | ویژگیهایی که با هم یا با خروجی بسیار همبستهاند را حذف میکند. | کاهش ویژگیهای تکراری | فقط برای روابط خطی مفید است |
Wrapper Methods (روشهای بستهبندی)
در این روشها، یک مدل یادگیری (مثلاً Logistic Regression یا Random Forest) انتخاب میشود و ویژگیها بر اساس عملکرد واقعی مدل ارزیابی میگردند. این روشها دقیقتر ولی بسیار کندتر از Filterها هستند.

| روش | توضیح | مزایا | معایب |
|---|---|---|---|
| Forward Selection | ویژگیها از صفر شروع شده و یکییکی اضافه میشوند تا عملکرد بهتر شود. | ساده و قابل فهم | زمانبر برای ویژگیهای زیاد |
| Backward Elimination | از تمام ویژگیها شروع و به تدریج ویژگیهای کماهمیت حذف میشوند. | کنترل دقیق روی عملکرد مدل | پرهزینه از نظر محاسباتی |
| Recursive Feature Elimination (RFE) | مدل آموزش داده میشود و در هر مرحله ضعیفترین ویژگی حذف میشود. | پرکاربرد با SVM و Random Forest | نیاز به اجرای مکرر مدل |
| Sequential Feature Selector (SFS) | نسخهی کلیتر Forward و Backward Selection با تنظیمات منعطفتر در scikit-learn | ترکیب سرعت و دقت | همچنان کند برای دادههای بزرگ |
Embedded Methods (درونمدلی)
در روشهای Embedded، انتخاب ویژگی در حین آموزش مدل اتفاق میافتد. این رویکرد ترکیبی از سرعت فیلترها و دقت Wrapperها است.این روشها در حین آموزش مدل ویژگیهای مهم رو انتخاب میکند.
| روش | توضیح | مدلهای مناسب | مزایا | معایب |
|---|---|---|---|---|
| Lasso (L1 Regularization) | ویژگیهای بیاهمیت را با صفر کردن وزن آنها حذف میکند. | مدلهای خطی (Lasso, Logistic) | ساده و سریع | فقط برای روابط خطی مفید است |
| Ridge / ElasticNet | مشابه Lasso ولی با کنترل بیشتر روی همبستگی ویژگیها | دادههای همبسته | پایداری بیشتر نسبت به Lasso | تفسیر سختتر |
| Tree-based Importance (RF, XGBoost) | اهمیت ویژگیها را بر اساس میزان بهبود دقت در گرهها میسنجد. | مدلهای درختی | پشتیبانی از روابط غیرخطی | تفسیرپذیری کمتر |
| Gradient Boosting Gain | بر اساس “Gain” یا افزایش دقت در تقسیم دادهها | مدلهای boosting مثل LightGBM | دقت بسیار بالا | حساس به پارامترها |
Hybrid / Advanced Methods (ترکیبی و مدرن)
در این دسته، از ترکیب چند روش فیلتر، بستهبندی یا درونمدلی استفاده میشود تا عملکرد پایدارتر و دقیقتری حاصل شود.
| روش | توضیح | مزایا | معایب |
|---|---|---|---|
| Relief / ReliefF | ویژگیها را بر اساس تفاوت میان همسایههای نزدیک از کلاسهای مختلف ارزیابی میکند. | مقاوم در برابر نویز | حساس به مقیاس داده |
| mRMR (Minimum Redundancy Maximum Relevance) | ویژگیهایی را انتخاب میکند که هم مرتبط با خروجی باشند و با هم تکراری نباشند. | محبوب در دادههای زیاد (مثلاً EEG یا ژنتیک) | نیاز به محاسبات زیاد |
| Boruta Algorithm | بر پایهی Random Forest توسعه یافته و با ایجاد ویژگیهای تصادفی (Shadow Features) انتخاب دقیقتری ارائه میدهد. | پایداری بالا در دادههای noisy | زمانبر ولی دقیق |
نکات مهم در انتخاب ویژگی
- در دادههای با ابعاد بالا (High-Dimensional Data)، روشهای فیلتر یا ترکیبی (mRMR, Boruta) معمولاً بهترین انتخاب هستند.
- قبل از انتخاب ویژگی، نرمالسازی (Normalization) و حذف دادههای پرت (Outliers) را انجام دهید.
- روش انتخاب ویژگی باید با نوع مدل یادگیری سازگار باشد. مثلاً RFE با SVM یا RandomForest بهتر عمل میکند.
جمعبندی
| نوع روش | سرعت | دقت | وابسته به مدل | مثالهای معروف |
|---|---|---|---|---|
| Filter | بسیار بالا | متوسط | ❌ | Fisher, Chi2, MI |
| Wrapper | پایین | بالا | ✅ | RFE, SFS |
| Embedded | بالا | بالا | ✅ | Lasso, RF |
| Hybrid | متوسط | بسیار بالا | نیمهوابسته | Boruta, mRMR |
مثال کوتاه از چند روش مهم (با sklearn)
در ادامه چند مدل فراخوانی کتابخانه sklearn برای انتخاب ویزگی را مشاهده می کنیم.
from sklearn.feature_selection import SelectKBest, chi2, f_classif, mutual_info_classif
from sklearn.linear_model import LassoCV
from sklearn.feature_selection import RFE
from sklearn.ensemble import RandomForestClassifier
# 1️⃣ ANOVA F-test
anova_selector = SelectKBest(score_func=f_classif, k=20)
xtrain_anova = anova_selector.fit_transform(xtrain, ytrain)
selected_anova = anova_selector.get_support(indices=True)
# 2️⃣ Mutual Information
mi_selector = SelectKBest(score_func=mutual_info_classif, k=20)
xtrain_mi = mi_selector.fit_transform(xtrain, ytrain)
selected_mi = mi_selector.get_support(indices=True)
# 3️⃣ LASSO (Embedded)
lasso = LassoCV(cv=5, random_state=42).fit(xtrain, ytrain)
selected_lasso = np.where(lasso.coef_ != 0)[0]
# 4️⃣ RFE (Wrapper)
rf = RandomForestClassifier(random_state=42)
rfe = RFE(rf, n_features_to_select=20)
xtrain_rfe = rfe.fit_transform(xtrain, ytrain_bal)
selected_rfe = np.where(rfe.support_)[0]











