
دستهبندی الگوریتمهای رگرسیون


رگرسیون چیست؟
رگرسیون یکی از روشهای مهم در آمار و یادگیری ماشین است که برای مدلسازی رابطه بین یک متغیر وابسته و یک یا چند متغیر مستقل استفاده میشود. متغیر وابسته همان مقداری است که قصد داریم آن را پیشبینی کنیم، در حالی که متغیرهای مستقل عواملی هستند که میتوانند بر مقدار خروجی تأثیر بگذارند.
بهطور کلی، رابطه رگرسیونی را میتوان به شکل زیر نمایش داد:
در این رابطه، Y متغیر وابسته، متغیر یا متغیرهای مستقل، تابعی برای بیان رابطه بین ورودی و خروجی، و ε نشاندهنده خطا یا نویز مدل است. هدف اصلی در رگرسیون این است که تابعی پیدا شود که بتواند مقدار خروجی را با کمترین خطا پیشبینی کند.
انواع رگرسیون
الگوریتمهای رگرسیون را میتوان از دیدگاههای مختلفی دستهبندی کرد. برخی منابع این الگوریتمها را بر اساس شکل رابطه بین ورودی و خروجی، برخی بر اساس نوع تابع هزینه، و برخی دیگر بر اساس ساختار مدل بررسی میکنند. در ادامه، مهمترین دستههای الگوریتمهای رگرسیون معرفی میشوند.
۱. رگرسیونهای خطی
در رگرسیونهای خطی، فرض میشود که رابطه بین متغیرهای ورودی و خروجی بهصورت خطی است. این روشها به دلیل سادگی، تفسیرپذیری بالا و کاربرد گسترده، از پرکاربردترین مدلهای رگرسیونی هستند.مهمترین روشهای این دسته عبارتاند از:
- رگرسیون خطی ساده
- رگرسیون خطی چندگانه
در رگرسیون خطی، مدل تلاش میکند با استفاده از یک رابطه خطی، مقدار خروجی را پیشبینی کند. رایجترین روش برای آموزش این مدل، روش حداقل مربعات خطا است. در این روش، مدل ضرایبی را انتخاب میکند که مجموع مربع اختلاف بین مقدار واقعی و مقدار پیشبینیشده کمینه شود.
«برای اطلاعات بیشتر مقاله رگرسیون خطی و چند جملهای را مطالعه کنید.»
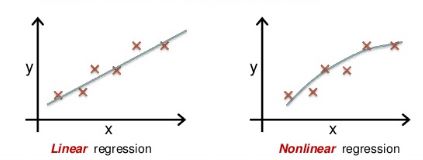
۲. رگرسیونهای غیرخطی
در بعضی مسائل، رابطه بین ورودیها و خروجی بهصورت خطی نیست. در چنین شرایطی، استفاده از رگرسیون خطی ساده ممکن است دقت کافی نداشته باشد. رگرسیونهای غیرخطی برای مدلسازی روابط پیچیدهتر، منحنیشکل یا غیرخطی به کار میروند. نمونههای مهم این دسته عبارتاند از:
- رگرسیون چندجملهای
- رگرسیون نمایی
- رگرسیون لگاریتمی
- رگرسیون تواندار
رگرسیون چندجملهای یکی از رایجترین روشهای غیرخطی است. در این روش، توانهای مختلفی از متغیر ورودی به مدل اضافه میشوند تا رابطه غیرخطی بین ورودی و خروجی بهتر نمایش داده شود.
۳. رگرسیونهای منظمسازیشده
اهی مدل بیش از حد به دادههای آموزشی وابسته میشود و عملکرد خوبی روی دادههای جدید ندارد. به این مشکل بیشبرازش یا Overfitting گفته میشود. رگرسیونهای منظمسازیشده برای کاهش بیشبرازش و کنترل پیچیدگی مدل استفاده میشوند.
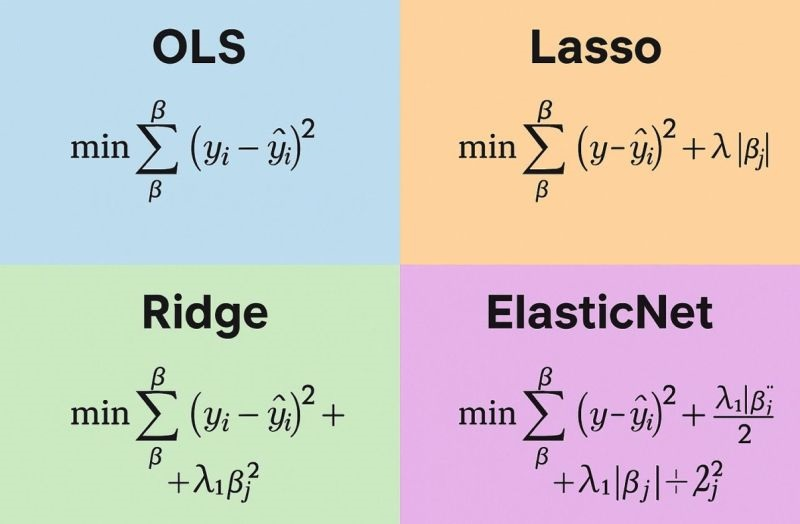
در این روشها، علاوه بر خطای پیشبینی، یک جمله جریمه نیز به تابع هزینه اضافه میشود. این جریمه باعث میشود ضرایب مدل بیش از حد بزرگ نشوند و مدل سادهتر و پایدارتر باقی بماند. مهمترین روشهای این دسته عبارتاند از:
- رگرسیون ریج
- رگرسیون لاسو
- رگرسیون الاستیکنت
در رگرسیون ریج از جریمه L2 استفاده میشود و ضرایب مدل کوچکتر میشوند. در رگرسیون لاسو از جریمه L1 استفاده میشود و بعضی ضرایب میتوانند دقیقاً صفر شوند؛ به همین دلیل لاسو برای انتخاب ویژگی نیز کاربرد دارد. الاستیکنت ترکیبی از ریج و لاسو است و از هر دو نوع جریمه استفاده میکند.
«برای اطلاعات بیشتر مقاله رگرسیون خطی و چند جملهای را مطالعه کنید.»
۴. رگرسیونهای درختی
رگرسیونهای درختی بهجای استفاده از یک معادله خطی یا فرمول ثابت، دادهها را به چند بخش کوچکتر تقسیم میکنند. سپس برای هر بخش، یک مقدار خروجی پیشبینی میشود. این مدلها برای دادههایی که روابط پیچیده و غیرخطی دارند، بسیار کاربردی هستند. مهمترین روشهای این دسته عبارتاند از:
- رگرسیون درخت تصمیم
- رگرسیون جنگل تصادفی
- رگرسیون گرادیان بوستینگ
- XGBoost Regression
- LightGBM Regression
- CatBoost Regression
درخت تصمیم ساختاری ساده و قابل فهم دارد، اما ممکن است دچار بیشبرازش شود. برای حل این مشکل، روشهایی مانند جنگل تصادفی و گرادیان بوستینگ توسعه یافتهاند. جنگل تصادفی با ترکیب چندین درخت، دقت و پایداری مدل را افزایش میدهد. مدلهای XGBoost، LightGBM و CatBoost نیز از روشهای پیشرفته مبتنی بر بوستینگ هستند.
۵. رگرسیونهای مبتنی بر بردار پشتیبان
رگرسیون بردار پشتیبان یا SVR یکی دیگر از روشهای مهم رگرسیون است. در این روش، هدف این است که تابعی پیدا شود که بیشترین تعداد دادهها را در یک محدوده خطای قابل قبول قرار دهد.
SVR برای دادههایی مناسب است که رابطه بین ورودی و خروجی پیچیده است. همچنین با استفاده از توابع کرنل، میتوان روابط غیرخطی را نیز مدلسازی کرد. بنابراین این روش هم برای مسائل خطی و هم برای مسائل غیرخطی قابل استفاده است.
۶. رگرسیونهای احتمالاتی و تعمیمیافته
در برخی مسائل، نوع خروجی یا توزیع دادهها با فرضیات رگرسیون خطی معمولی سازگار نیست. در چنین شرایطی از مدلهای احتمالاتی و تعمیمیافته استفاده میشود. این مدلها بیشتر در آمار، علوم پزشکی، اقتصاد و تحلیل دادههای شمارشی کاربرد دارند. نمونههای مهم این دسته عبارتاند از:
- رگرسیون لجستیک
- رگرسیون پواسون
- رگرسیون باینومیال
- رگرسیون گاما
رگرسیون لجستیک با وجود اینکه نام رگرسیون دارد، بیشتر برای مسائل طبقهبندی استفاده میشود. خروجی آن معمولاً احتمال تعلق یک نمونه به یک کلاس خاص است. رگرسیون پواسون نیز برای دادههای شمارشی، مانند تعداد رخدادها، تعداد تماسها یا تعداد مراجعهها کاربرد دارد.
۷. رگرسیونهای مبتنی بر شبکه عصبی
شبکههای عصبی یکی از روشهای قدرتمند برای مدلسازی روابط پیچیده بین دادهها هستند. زمانی که حجم داده زیاد باشد یا رابطه بین ورودی و خروجی بسیار پیچیده باشد، میتوان از شبکههای عصبی برای مسائل رگرسیونی استفاده کرد.نمونههای این دسته عبارتاند از:
- شبکه عصبی پرسپترون چندلایه برای رگرسیون
- مدلهای عمیق برای رگرسیون
- CNN Regression
- RNN/LSTM Regression
این مدلها در حوزههایی مانند پردازش تصویر، تحلیل سیگنال، سریهای زمانی و دادههای پزشکی کاربرد زیادی دارند. برای مثال، در تحلیل سیگنالهای سری زمانی میتوان از شبکههای عصبی برای پیشبینی ویژگیهای عددی یا تحلیل الگوهای پیچیده در داده های سری زمانی استفاده کرد.
مقایسه کلی الگوریتمهای رگرسیون
هر الگوریتم رگرسیون برای نوع خاصی از داده و مسئله مناسبتر است. اگر رابطه بین متغیرها ساده و خطی باشد، رگرسیون خطی انتخاب مناسبی است. اگر دادهها الگوی منحنیشکل داشته باشند، رگرسیون غیر خطی میتواند عملکرد بهتری داشته باشد.
در شرایطی که مدل دچار بیشبرازش میشود یا تعداد ویژگیها زیاد است، روشهایی مانند ریج، لاسو و الاستیکنت مفید هستند. اگر دادهها روابط پیچیده، غیرخطی و تعاملات زیاد بین ویژگیها داشته باشند، مدلهای درختی، SVR یا شبکههای عصبی میتوانند گزینههای مناسبتری باشند.
| اگر هدف این باشد | دسته مناسب |
|---|---|
| مدل ساده و قابل توضیح | رگرسیون خطی |
| رابطه منحنی مشخص | رگرسیون غیرخطی |
| کنترل Overfitting | Ridge / LASSO / Elastic Net |
| دقت بالا روی داده جدولی | Random Forest / XGBoost / LightGBM |
| داده کوچک ولی پیچیده | SVR |
| خروجی احتمال یا شمارشی | Logistic / Poisson |
| سیگنال، تصویر یا سری زمانی پیچیده | شبکه عصبی / CNN / LSTM |
معیارهای ارزیابی مدلهای رگرسیون
برای بررسی کیفیت عملکرد مدلهای رگرسیون، از معیارهای مختلفی استفاده میشود. این معیارها نشان میدهند که مقدار پیشبینیشده توسط مدل تا چه اندازه به مقدار واقعی نزدیک است.مهمترین معیارهای ارزیابی عبارتاند از:
میانگین مربعات خطا یا MSE:
ریشه میانگین مربعات خطا یا RMSE:
$$ RMSE = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i – \hat{y}_i)^2} $$
میانگین قدر مطلق خطا یا MAE:
ضریب تعیین یا R²:
هرچه مقادیر MSE، RMSE و MAE کمتر باشند، مدل عملکرد بهتری دارد. همچنین هرچه مقدار R² بزرگتر باشد، مدل توانسته است بخش بیشتری از تغییرات داده را توضیح دهد.
جمعبندی دستهبندی
به طور کلی، الگوریتمهای رگرسیون را میتوان به چند گروه اصلی تقسیم کرد:
- رگرسیونهای خطی
- رگرسیونهای غیرخطی
- رگرسیونهای منظمسازیشده
- رگرسیونهای درختی
- رگرسیونهای بردار پشتیبان
- رگرسیونهای احتمالاتی و تعمیمیافته
- رگرسیونهای مبتنی بر شبکه عصبی
انتخاب الگوریتم مناسب به نوع داده، شکل رابطه بین متغیرها، میزان پیچیدگی مسئله و هدف تحلیل بستگی دارد. اگر دادهها ساده و قابل تفسیر باشند، رگرسیون خطی گزینه خوبی است. اگر رابطهها پیچیده و غیرخطی باشند، مدلهایی مانند رگرسیون درختی، SVR یا شبکههای عصبی میتوانند عملکرد بهتری داشته باشند. همچنین اگر هدف کاهش بیشبرازش و افزایش پایداری مدل باشد، روشهایی مانند ریج، لاسو و الاستیکنت کاربرد زیادی دارند.











