
نرمالسازی و استانداردسازی در ML: راهنمای پیشپردازش دادهها


در یادگیری ماشین، پیشپردازش دادهها یکی از مراحل حیاتی برای بهبود عملکرد مدلهاست. ویژگیهای داده با مقیاسها و دامنههای متفاوت میتوانند الگوریتمها را به سمت اولویتبندی نادرست سوق دهند، که این امر به کاهش دقت و کارایی مدل منجر میشود. نرمالسازی و استانداردسازی دو تکنیک کلیدی پیشپردازش هستند که با یکنواختسازی مقیاس ویژگیها، همگرایی سریعتر و دقت بالاتر مدلها را تضمین میکنند. این مقاله به بررسی این دو تکنیک و سایر روشهای نرمالسازی میپردازد و با ارائه مثالها و مقایسهها، به درک بهتر کاربردهای آنها کمک میکند.
یادگیری ماشین و اهمیت پیشپردازش دادهها
یادگیری ماشین شاخهای از هوش مصنوعی است که الگوریتمهایی را توسعه میدهد تا از دادهها الگوهای معنادار استخراج کرده و پیشبینیهای دقیق انجام دهند. از منظر آماری، این فرآیند شامل تخمین پارامترهای مدل بر اساس توزیع دادههاست. اما ناهمگونی در مقیاس ویژگیها—مانند تفاوت بین وزن یک سیب (100 گرم) و یک بطری آب (1500 گرم)—میتواند باعث شود الگوریتمهایی مانند K-نزدیکترین همسایه (KNN)، ماشین بردار پشتیبان (SVM) یا شبکههای عصبی، به ویژگیهای با مقیاس بزرگتر وزن بیشتری بدهند. این ناهماهنگی میتواند نرخ یادگیری را کند کرده و به بهینهسازی نامناسب منجر شود.
پیشپردازش دادهها از طریق تکنیکهای نرمالسازی و استانداردسازی این مشکل را حل میکند. این روشها ویژگیها را به مقیاسهای یکنواخت تبدیل میکنند، بهطوریکه همه ویژگیها بهطور عادلانه در فرآیند یادگیری مشارکت کنند. این کار نهتنها همگرایی مدل را تسریع میکند، بلکه تعمیمپذیری و دقت پیشبینی را بهبود میبخشد.
ضرورت پیشپردازش دادهها
در دادهکاوی و یادگیری ماشین، ویژگیهای با مقیاسهای متفاوت میتوانند تأثیر نامتوازنی بر مدل بگذارند. برای مثال، در یک مجموعه داده شامل قد افراد (150-200 سانتیمتر) و درآمد سالانه (0-100 میلیون تومان)، بدون پیشپردازش، مدل ممکن است درآمد را بهعنوان ویژگی غالب تفسیر کند، حتی اگر قد اهمیت بیشتری در تحلیل داشته باشد. این ناهماهنگی میتواند به خطای تعمیم و کاهش دقت پیشبینی منجر شود. تکنیکهای نرمالسازی و استانداردسازی با تنظیم مقیاس ویژگیها، این ناهماهنگی را برطرف کرده و به الگوریتمها کمک میکنند تا بهطور مؤثرتری عمل کنند.
روشهای نرمالسازی و استانداردسازی
روش های متنوعی برای نرمال سازی و تغییر مقیاس داده ها وجود دارد برای هر کدام فرمول و مثال عددی آورده شده است.

1. نرمالسازی مین-مکس (Min-Max Scaling)
این روش دادهها را به یک بازه مشخص، معمولاً [0, 1] یا [-1, 1]، تبدیل میکند.
مثال: فرض کنید مجموعه داده وزنی اسباببازیها شامل [۲۰, ۴۰, ۶۰, ۸۰, ۱۰۰] باشد. حداقل = ۲۰، حداکثر = ۱۰۰.
نرمالسازی مقدار ۶۰:
\frac{60 – 20}{100 – 20} = \frac{40}{80} = 0.5
$$
مجموعه جدید: [۰, ۰.۲۵, ۰.۵, ۰.۷۵, ۱].
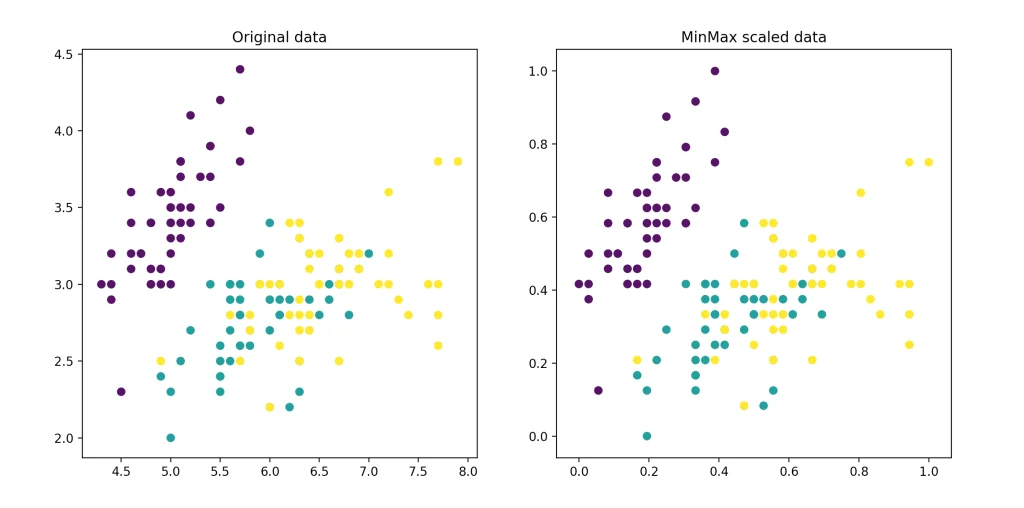
- کاربرد: در شبکههای عصبی، پردازش تصویر (پیکسلهای 0-255)، و الگوریتمهای مبتنی بر فاصله مانند KNN.
- مزایا: ساده، حفظ نسبتهای نسبی، مناسب برای دادههای با دامنه مشخص.
- معایب: حساس به مقادیر پرت (Outliers)، زیرا حداقل و حداکثر تحت تأثیر آنها قرار میگیرند.
2. استانداردسازی (Z-Score Normalization)
استاندارد سازی یا همان Standardization، دادهها را به گونهای تبدیل میکند که میانگین صفر و انحراف معیار یک داشته باشند.
که (mu) میانگین و (sigma) انحراف معیار است.
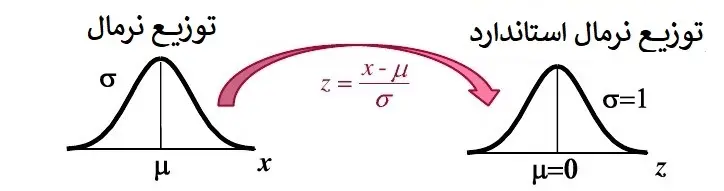
مثال: برای دادههای [10, 20, 25, 30, 40]، میانگین = 25، انحراف معیار ≈ 11.18. برای مقدار 30:
- کاربرد: در تحلیل مؤلفههای اصلی (PCA)، رگرسیون لجستیک، و SVM که فرض توزیع نرمال دارند.
- مزایا: مقاومتر در برابر پرتها، حفظ توزیع اصلی داده.
- معایب: دادهها به بازه خاصی محدود نمیشوند، ممکن است برای دادههای غیرنرمال نیاز به تبدیل اضافی داشته باشد.
3. نرمالسازی میانگین (Mean Normalization)
در نرمال سازی میانگین دادهها را حول میانگین تنظیم میکند تا میانگین صفر شود، اما انحراف معیار تغییر نمیکند.
مثال: برای دادههای [10, 20, 25, 30, 40]، میانگین = 25، حداقل = 10، حداکثر = 40. برای مقدار 30:
X’ = \frac{30 – 25}{40 – 10} = \frac{5}{30} \approx 0.17
$$
- کاربرد: در مواردی که میخواهیم دادهها حول صفر متمرکز شوند، اما نیازی به توزیع نرمال نیست.
- مزایا: ساده و مناسب برای دادههای با پراکندگی متوسط.
- معایب: حساس به داده های پرت، مشابه مین-مکس.
4. مقیاسبندی حداکثر مطلق (Maximum Absolute Scaling)
دادهها را با تقسیم بر حداکثر قدر مطلق مقادیر داده ها، مقیاس بندی میکند.
مثال: برای دادههای [-5, 2, 8, -10, 3]، (|Xmax =|- 10). برای مقدار 8:
- کاربرد: در دادههای پراکنده (مانند دادههای متنی) یا زمانی که دادهها شامل مقادیر مثبت و منفی هستند.
- مزایا: مناسب برای دادههای پراکنده، و سادگی روش.
- معایب: حساس به داده های پرت.
5. نرمالسازی با میانه و دامنه بینچارک (Median and IQR Normalization)
این روش نرمال سازی، دادهها را با استفاده از میانه و دامنه بینچارک (IQR = Q3 – Q1) نرمالسازی میکند.
مثال: برای دادههای [10, 20, 25, 30, 100]، میانه = 25، Q1 = 15، Q3 = 65، IQR = 50. برای مقدار 30:
- کاربرد: در دادههایی با پرتهای زیاد، مانند دادههای مالی.
- مزایا: مقاوم در برابر داده های پرت.
- معایب: محاسبات پیچیدهتر.
6. مقیاسبندی به نرم بردار (Scaling to Vector Norm)
این روش دادهها را به گونهای مقیاسبندی میکند که نرم بردار (مانند نرم L2) برابر با یک شود. فرمول نرم L2 به صورت زیر بیان شده است:
مثال:در بردار [3, 4]، برای مقدار عددی 3:
- کاربرد: در تحلیل معنایی نهان (LSA) یا پردازش سیگنال.
- مزایا: حفظ نسبتهای برداری.
- معایب: محاسبات پیچیدهتر.
7. نرمالسازی لگاریتمی (Log Normalization)
دادهها را با استفاده از تابع لگاریتم مقیاس دهی میکند تا توزیع با چولگی (توزیع نامنقارن) را اصلاح کند. مقدار (c) برای جلوگیری از صفر شدن درون پرانتز لگاریتم اضافه میشود.
مثال: برای دادههای [1, 10, 100, 1000]، با (c=1):
- کاربرد: در دادهها با چولگی مانند دادههای مالی یا زمانی.
- مزایا: کاهش اثر مقادیر بزرگ.
- معایب: برای دادههای منفی یا صفر نیاز به تنظیم دارد.
8. نرمالسازی توان (Power Transformation)
از تبدیلهای توانی (مانند Box-Cox یا Yeo-Johnson) برای پایدار کردن واریانس استفاده میکند. فرمول Box-Cox به صورت زیر است:
X’ =
\begin{cases}
\dfrac{X^{\lambda} – 1}{\lambda}, & \lambda \neq 0 \\[6pt]
\log(X), & \lambda = 0
\end{cases}
$$
- کاربرد: دادههای با واریانس ناپایدار.
- مزایا: انعطافپذیر، مناسب برای دادههای غیرنرمال.
- معایب: نیاز به تنظیم پارامتر (lambda).
مقایسه روشهای نرمالسازی و استانداردسازی
| معیار | مین-مکس | استانداردسازی | میانگین | حداکثر مطلق | میانه و IQR | نرم بردار | لگاریتمی | توان |
|---|---|---|---|---|---|---|---|---|
| بازه خروجی | [0, 1] یا دلخواه | بی محدودیت | [-1, 1] | [-1, 1] | بی محدودیت | [0, 1] | بی محدودیت | بی محدودیت |
| مزایا | ساده، مناسب برای بازه مشخص | مقاوم به دادهای پرتها، حفظ توزیع | ساده، متمرکز حول صفر | مناسب دادههای پراکنده | مقاوم به دادهای پرتها | حفظ نسبتهای برداری | اصلاح توزیع با چولگی (غیرمتقارن) | پایدارسازی واریانس |
| معایب | حساس به دادهای پرتها | بدون بازه ثابت | حساس به دادهای پرتها | حساس به دادهای پرتها | محاسبات پیچیده | محاسبات پیچیده | نیاز به تنظیم برای دادههای منفی | نیاز به تنظیم (lambda) |
| کاربرد | شبکههای عصبی، KNN | PCA، SVM | دادههای با پراکندگی متوسط | دادههای پراکنده | دادههای با دادهای پرت زیاد | LSA، پردازش سیگنال | دادهها با چولگی | دادههای غیرنرمال |
نکات کلیدی در انتخاب روش نرمالسازی
- توزیع دادهها: برای دادههای با چولگی، روشهای لگاریتمی یا توان مناسبترند.
- حساسیت به داده های پرت: استانداردسازی و میانه/IQR در برابر داد های پرت مقاومترند.
- الگوریتم هدف: شبکههای عصبی به مین-مکس یا استانداردسازی، و SVM/رگرسیون لجستیک به استانداردسازی حساساند.
- نوع داده: دادههای پراکنده از حداکثر مطلق و دادههای برداری از نرم بردار سود میبرند.
کدام الگورتیم ها به نرمالسازی نیاز دارند؟
الگوریتمهای نیازمند نرمالسازی: الگوریتمهایی مانند K-نزدیکترین همسایه (KNN)، ماشین بردار پشتیبان (SVM) و شبکههای عصبی به نرمالسازی دادهها نیاز دارند، زیرا به مقیاس ویژگیها حساساند. در KNN، فاصله بین نقاط (مانند فاصله اقلیدسی) مبنای تصمیمگیری است؛ اگر ویژگیها مقیاسهای متفاوتی داشته باشند (مثلاً درآمد در میلیونها و سن در سالها)، ویژگی با مقیاس بزرگتر تأثیر غالبتری بر فاصله خواهد داشت و پیشبینی را منحرف میکند. در SVM، بهینهسازی حاشیه به اختلاف مقیاس ویژگیها حساس است و نرمالسازی به ایجاد تعادل در تأثیر ویژگیها کمک میکند. شبکههای عصبی نیز به دلیل استفاده از بهینهسازی گرادیانی (مانند گرادیان نزولی) به دادههای نرمالشده نیاز دارند، زیرا مقیاسهای ناهمگون میتوانند گرادیانها را نامتعادل کرده و همگرایی را کند یا ناپایدار کنند.
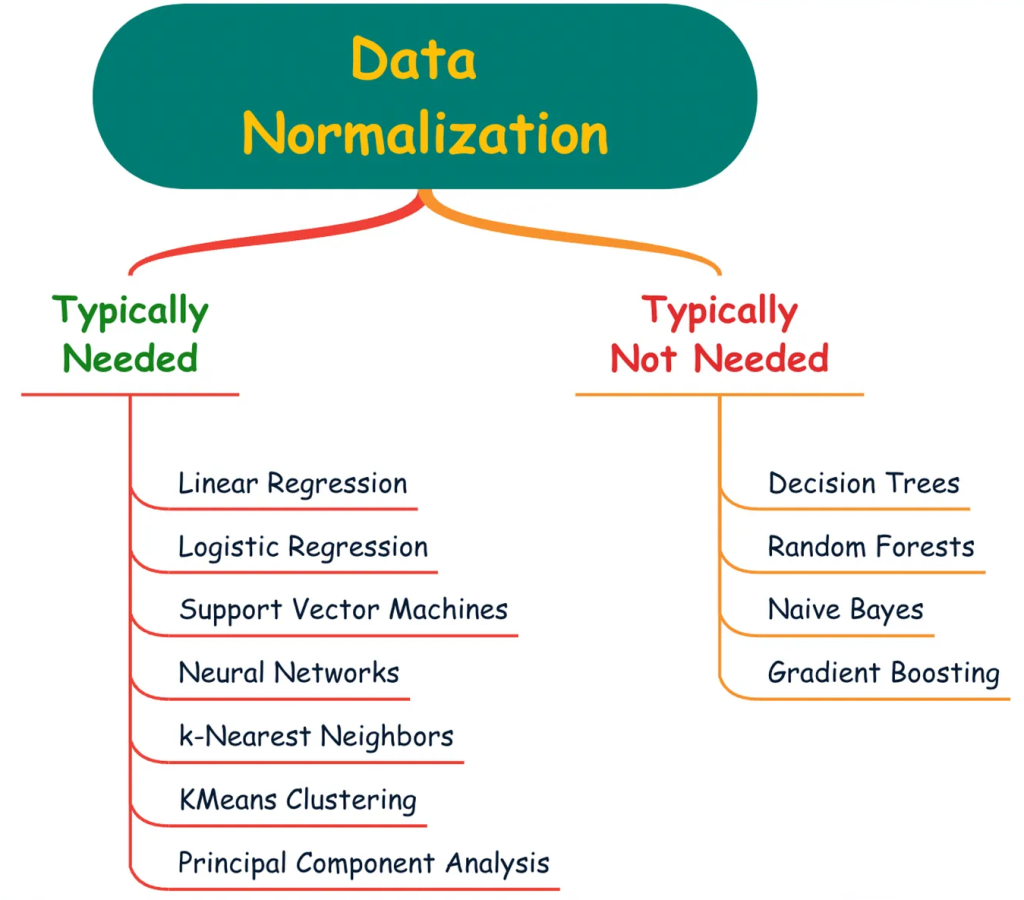
الگوریتمهای بینیاز به نرمالسازی: الگوریتمهایی مانند درخت تصمیم، جنگل تصادفی، بیز ساده و گرادیان بوستینگ به نرمالسازی نیاز ندارند، زیرا عملکرد آنها به مقیاس مطلق ویژگیها وابسته نیست. درخت تصمیم و جنگل تصادفی بر اساس آستانههای نسبی در ویژگیها (مانند «اگر x > 5») تصمیمگیری میکنند، بنابراین مقیاس ویژگی تأثیری بر تقسیمبندی دادهها ندارد. بیز ساده (Naive Bayes) بر احتمالهای شرطی وابسته است و مقیاس دادهها در محاسبات آن بیتأثیر است. گرادیان بوستینگ نیز، بهعنوان مجموعهای از درختهای تصمیم، به مقیاس ویژگیها حساس نیست، زیرا هر درخت بهصورت مستقل آستانههای خود را تعیین میکند. در نتیجه، این الگوریتمها بدون نرمالسازی هم عملکرد پایداری دارند، که باعث صرفهجویی در زمان پیشپردازش میشود.
نتیجهگیری
نرمالسازی و استانداردسازی ابزارهای قدرتمندی برای پیشپردازش دادهها در یادگیری ماشین هستند که با یکنواختسازی مقیاس ویژگیها، دقت و کارایی مدلها را بهبود میبخشند. انتخاب روش مناسب به عواملی مانند توزیع دادهها، وجود پرتها، و نوع الگوریتم بستگی دارد. برای مثال، نرمالسازی مین-مکس برای دادههای با دامنه مشخص و استانداردسازی برای دادههای با توزیع نزدیک به نرمال ایدهآل است. روشهای دیگر مانند نرمالسازی با میانه و IQR یا لگاریتمی در موارد خاص مانند دادههای با پرتهای زیاد یا توزیع نامتقارن کاربرد دارند. مطالعات نشان میدهند که عدم استفاده از پیشپردازش مناسب میتواند عملکرد مدل را تا 20-30٪ کاهش دهد. ابزارهایی مانند Scikit-learn در پایتون (مانند MinMaxScaler و StandardScaler) این فرآیند را سادهتر کردهاند. انتخاب هوشمندانه روش نرمالسازی، کلید دستیابی به مدلهای دقیق و پایدار در یادگیری ماشین است.











